Data Jobs Monitoring helps you observe, troubleshoot, and cost-optimize your Databricks jobs and clusters.
This page is limited to documentation for ingesting Databricks cluster utilization metrics and logs.
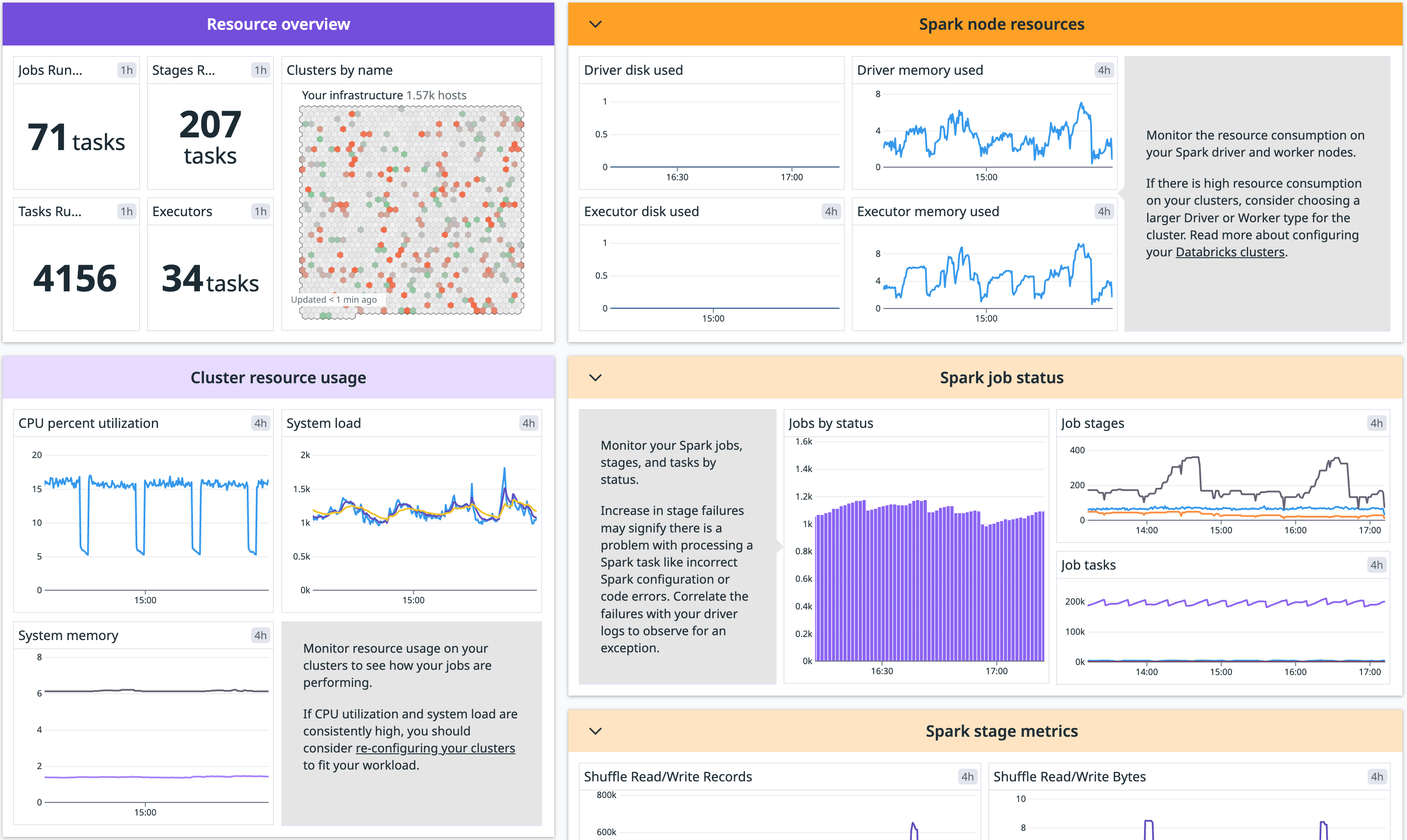
概要
Databricks クラスターを Datadog の Spark インテグレーションで監視します。
このインテグレーションは、ログ、インフラストラクチャーメトリクス、Spark パフォーマンスメトリクスを統合し、ノードの健全性とジョブのパフォーマンスをリアルタイムで視覚化します。エラーのデバッグ、パフォーマンスの微調整、非効率なデータ分割やクラスターのメモリ不足などの問題の特定に役立ちます。
機能の詳細については、Datadog を使用した Databricks の監視を参照してください。
セットアップ
インストール
Databricks Spark アプリケーションを Datadog Spark インテグレーションで監視します。適切なクラスターの構成方法に従って、クラスターに Datadog Agent をインストールしてください。その後、Datadog に Spark インテグレーションをインストールし、Databricks Overview ダッシュボードを自動インストールします。
構成
Databricks で Apache Spark クラスターを監視し、システムと Spark のメトリクスを収集するように Sparkインテグレーションを構成します。
以下に説明する各スクリプトは、ニーズに合わせて変更することができます。例えば、
- インスタンスに特定のタグを追加することができます。
- Spark インテグレーション構成を変更することができます。
UI、Databricks CLI を使用して、または Clusters API を呼び出して、クラスタースコープの init スクリプトパスで環境変数を定義または変更することもできます。
DD_API_KEY を設定することで、クラスターを識別しやすくなります。DD_ENV を設定することで、クラスターを識別しやすくなります。DD_SITE をサイトに設定します: datadoghq.com です。
セキュリティ上の理由から、環境変数 `DD_API_KEY` を UI で直接プレーンテキストで定義することは推奨されません。代わりに
Databricks シークレットを使用してください。
グローバル init スクリプトの場合
グローバル init スクリプトは、ワークスペースで作成されたすべてのクラスターで実行されます。グローバル init スクリプトは、組織全体のライブラリ構成やセキュリティ画面を強制したい場合に便利です。
ワークスペース管理者のみがグローバル init スクリプトを管理できます。
Databricks UI を使用してグローバル init スクリプトを編集します。
- 以下のスクリプトのいずれかを選択して、Agent をドライバー、またはクラスターのドライバーノードとワーカーノードにインストールします。
- ニーズに合わせてスクリプトを変更します。例えば、タグを追加したり、インテグレーション用に特定の構成を定義することができます。
- 管理者設定に移動し、Global Init Scripts タブをクリックします。
- + Add ボタンをクリックします。
Datadog init script のようにスクリプトに名前を付けて、** Script** フィールドに貼り付けます。- Enabled トグルをクリックして有効にします。
- Add ボタンをクリックします。
これらの手順の後、新しいクラスターは自動的にスクリプトを使用します。グローバル init スクリプトの詳細については Databricks 公式ドキュメントを参照してください。
複数の init スクリプトを定義し、UI でその順番を指定することができます。
ドライバーに Datadog Agent をインストールする
クラスターのドライバーノードに Datadog Agent をインストールします。
スクリプト内で `DD_API_KEY` 変数の値を定義する必要があります。
#!/bin/bash
cat <<EOF > /tmp/start_datadog.sh
#!/bin/bash
date -u +"%Y-%m-%d %H:%M:%S UTC"
echo "Running on the driver? \$DB_IS_DRIVER"
echo "Driver ip: \$DB_DRIVER_IP"
DB_CLUSTER_NAME=$(echo "$DB_CLUSTER_NAME" | sed -e 's/ /_/g' -e "s/'/_/g")
DD_API_KEY='<YOUR_API_KEY>'
if [[ \${DB_IS_DRIVER} = "TRUE" ]]; then
echo "Installing Datadog Agent on the driver..."
# ドライバーのホストタグを構成します
DD_TAGS="environment:\${DD_ENV}","databricks_cluster_id:\${DB_CLUSTER_ID}","databricks_cluster_name:\${DB_CLUSTER_NAME}","spark_host_ip:\${DB_DRIVER_IP}","spark_node:driver","databricks_instance_type:\${DB_INSTANCE_TYPE}","databricks_is_job_cluster:\${DB_IS_JOB_CLUSTER}"
# 最新の Datadog Agent 7 をドライバーノードとワーカーノードにインストールします
DD_INSTALL_ONLY=true \
DD_API_KEY=\$DD_API_KEY \
DD_HOST_TAGS=\$DD_TAGS \
DD_HOSTNAME="\$(hostname | xargs)" \
DD_SITE="\${DD_SITE:-datadoghq.com}" \
bash -c "\$(curl -L https://s3.amazonaws.com/dd-agent/scripts/install_script_agent7.sh)"
# ポート 6062 での競合を回避
echo "process_config.expvar_port: 6063" >> /etc/datadog-agent/datadog.yaml
echo "Datadog Agent is installed"
while [ -z \$DB_DRIVER_PORT ]; do
if [ -e "/tmp/driver-env.sh" ]; then
DB_DRIVER_PORT="\$(grep -i "CONF_UI_PORT" /tmp/driver-env.sh | cut -d'=' -f2)"
fi
echo "Waiting 2 seconds for DB_DRIVER_PORT"
sleep 2
done
echo "DB_DRIVER_PORT=\$DB_DRIVER_PORT"
# 構造化ストリーミングメトリクスを有効にし Spark インテグレーション用のコンフィギュレーションファイルを記述
# 他のオプションを spark.d/conf.yaml.example に含めるように変更します
echo "init_config:
instances:
- spark_url: http://\${DB_DRIVER_IP}:\${DB_DRIVER_PORT}
spark_cluster_mode: spark_driver_mode
cluster_name: \${DB_CLUSTER_NAME}
streaming_metrics: true
executor_level_metrics: true
logs:
- type: file
path: /databricks/driver/logs/*.log
source: spark
service: databricks
log_processing_rules:
- type: multi_line
name: new_log_start_with_date
pattern: \d{2,4}[\-\/]\d{2,4}[\-\/]\d{2,4}.*" > /etc/datadog-agent/conf.d/spark.d/spark.yaml
echo "Spark integration configured"
# datadog.yaml のログを有効にしてドライバーログを収集します
sed -i '/.*logs_enabled:.*/a logs_enabled: true' /etc/datadog-agent/datadog.yaml
fi
echo "Restart the agent"
sudo service datadog-agent restart
EOF
chmod a+x /tmp/start_datadog.sh
/tmp/start_datadog.sh >> /tmp/datadog_start.log 2>&1 & disown
Datadog Agent をドライバーノードとワーカーノードにインストールする
クラスターのドライバーノードとワーカーノードに Datadog Agent をインストールします。
スクリプト内で `DD_API_KEY` 変数の値を定義する必要があります。
#!/bin/bash
cat <<EOF > /tmp/start_datadog.sh
#!/bin/bash
date -u +"%Y-%m-%d %H:%M:%S UTC"
echo "Running on the driver? \$DB_IS_DRIVER"
echo "Driver ip: \$DB_DRIVER_IP"
DB_CLUSTER_NAME=$(echo "$DB_CLUSTER_NAME" | sed -e 's/ /_/g' -e "s/'/_/g")
DD_API_KEY='<YOUR_API_KEY>'
if [[ \${DB_IS_DRIVER} = "TRUE" ]]; then
echo "Installing Datadog Agent on the driver (master node)."
# ドライバー用のホストタグを構成する
DD_TAGS="environment:\${DD_ENV}","databricks_cluster_id:\${DB_CLUSTER_ID}","databricks_cluster_name:\${DB_CLUSTER_NAME}","spark_host_ip:\${DB_DRIVER_IP}","spark_node:driver","databricks_instance_type:\${DB_INSTANCE_TYPE}","databricks_is_job_cluster:\${DB_IS_JOB_CLUSTER}"
# 最新の Datadog Agent 7 をドライバーノードとワーカーノードにインストールする
DD_INSTALL_ONLY=true \
DD_API_KEY=\$DD_API_KEY \
DD_HOST_TAGS=\$DD_TAGS \
DD_HOSTNAME="\$(hostname | xargs)" \
DD_SITE="\${DD_SITE:-datadoghq.com}" \
bash -c "\$(curl -L https://s3.amazonaws.com/dd-agent/scripts/install_script_agent7.sh)"
echo "Datadog Agent is installed"
while [ -z \$DB_DRIVER_PORT ]; do
if [ -e "/tmp/driver-env.sh" ]; then
DB_DRIVER_PORT="\$(grep -i "CONF_UI_PORT" /tmp/driver-env.sh | cut -d'=' -f2)"
fi
echo "Waiting 2 seconds for DB_DRIVER_PORT"
sleep 2
done
echo "DB_DRIVER_PORT=\$DB_DRIVER_PORT"
# 構造化ストリーミングメトリクスを有効にし Spark インテグレーション用のコンフィギュレーションファイルを記述
# spark.d/conf.yaml.example に他のオプションを含めるように変更する
echo "init_config:
instances:
- spark_url: http://\${DB_DRIVER_IP}:\${DB_DRIVER_PORT}
spark_cluster_mode: spark_driver_mode
cluster_name: \${DB_CLUSTER_NAME}
streaming_metrics: true
executor_level_metrics: true
logs:
- type: file
path: /databricks/driver/logs/*.log
source: spark
service: databricks
log_processing_rules:
- type: multi_line
name: new_log_start_with_date
pattern: \d{2,4}[\-\/]\d{2,4}[\-\/]\d{2,4}.*" > /etc/datadog-agent/conf.d/spark.d/spark.yaml
echo "Spark integration configured"
# ドライバーのログを収集するために datadog.yaml でログを有効にする
sed -i '/.*logs_enabled:.*/a logs_enabled: true' /etc/datadog-agent/datadog.yaml
else
echo "Installing Datadog Agent on the worker."
# ワーカー用のホストタグを構成する
DD_TAGS="environment:\${DD_ENV}","databricks_cluster_id:\${DB_CLUSTER_ID}","databricks_cluster_name:\${DB_CLUSTER_NAME}","spark_host_ip:\${SPARK_LOCAL_IP}","spark_node:worker","databricks_instance_type:\${DB_INSTANCE_TYPE}","databricks_is_job_cluster:\${DB_IS_JOB_CLUSTER}"
# 最新の Datadog Agent 7 をドライバーノードとワーカーノードにインストールする
# バージョン 7.40 以上で Agent が失敗しないように、datadog.yaml でホスト名を明確に構成する
# 変更については https://github.com/DataDog/datadog-agent/issues/14152 をご覧ください
DD_INSTALL_ONLY=true DD_API_KEY=\$DD_API_KEY DD_HOST_TAGS=\$DD_TAGS DD_HOSTNAME="\$(hostname | xargs)" bash -c "\$(curl -L https://s3.amazonaws.com/dd-agent/scripts/install_script_agent7.sh)"
echo "Datadog Agent is installed"
fi
# ポート 6062 での競合を回避
echo "process_config.expvar_port: 6063" >> /etc/datadog-agent/datadog.yaml
echo "Restart the agent"
sudo service datadog-agent restart
EOF
chmod a+x /tmp/start_datadog.sh
/tmp/start_datadog.sh >> /tmp/datadog_start.log 2>&1 & disown
クラスタースコープの init スクリプトの場合
Cluster-scoped init scripts are init scripts defined in a cluster configuration. Cluster-scoped init scripts apply to both clusters you create and those created to run jobs. Databricks supports configuration and storage of init scripts through:
- Workspace Files
- Unity Catalog Volumes
- Cloud Object Storage
Databricks UI を使用してクラスターを編集し、init スクリプトを実行します。
- 以下のスクリプトのいずれかを選択して、Agent をドライバー、またはクラスターのドライバーノードとワーカーノードにインストールします。
- ニーズに合わせてスクリプトを変更します。例えば、タグを追加したり、インテグレーション用に特定の構成を定義することができます。
- Save the script into your workspace with the Workspace menu on the left. If using Unity Catalog Volume, save the script in your Volume with the Catalog menu on the left.
- クラスター構成ページで、** Advanced** オプションのトグルをクリックします。
- Environment variables で、
DD_API_KEY 環境変数と、オプションで DD_ENV と DD_SITE 環境変数を指定します。 - Init Scripts タブに移動します。
- In the Destination dropdown, select the
Workspace destination type. If using Unity Catalog Volume, in the Destination dropdown, select the Volume destination type. - Specify a path to the init script.
- Add ボタンをクリックします。
もし datadog_init_script.sh を Shared ワークスペースに直接保存した場合は、パス /Shared/datadog_init_script.sh でファイルにアクセスできます。
もし datadog_init_script.sh をユーザーワークスペースに直接保存した場合は、パス /Users/$EMAIL_ADDRESS/datadog_init_script.sh でファイルにアクセスできます。
If you stored your datadog_init_script.sh directly in a Unity Catalog Volume, you can access the file at the following path: /Volumes/$VOLUME_PATH/datadog_init_script.sh.
クラスター init スクリプトの詳細については、Databricks 公式ドキュメントを参照してください。
ドライバーに Datadog Agent をインストールします
クラスターのドライバーノードに Datadog Agent をインストールします。
#!/bin/bash
cat <<EOF > /tmp/start_datadog.sh
#!/bin/bash
date -u +"%Y-%m-%d %H:%M:%S UTC"
echo "Running on the driver? \$DB_IS_DRIVER"
echo "Driver ip: \$DB_DRIVER_IP"
DB_CLUSTER_NAME=$(echo "$DB_CLUSTER_NAME" | sed -e 's/ /_/g' -e "s/'/_/g")
if [[ \${DB_IS_DRIVER} = "TRUE" ]]; then
echo "Installing Datadog Agent on the driver..."
# ドライバーのホストタグを構成します
DD_TAGS="environment:\${DD_ENV}","databricks_cluster_id:\${DB_CLUSTER_ID}","databricks_cluster_name:\${DB_CLUSTER_NAME}","spark_host_ip:\${DB_DRIVER_IP}","spark_node:driver","databricks_instance_type:\${DB_INSTANCE_TYPE}","databricks_is_job_cluster:\${DB_IS_JOB_CLUSTER}"
# 最新の Datadog Agent 7 をドライバーノードとワーカーノードにインストールします
DD_INSTALL_ONLY=true \
DD_API_KEY=\$DD_API_KEY \
DD_HOST_TAGS=\$DD_TAGS \
DD_HOSTNAME="\$(hostname | xargs)" \
DD_SITE="\${DD_SITE:-datadoghq.com}" \
bash -c "\$(curl -L https://s3.amazonaws.com/dd-agent/scripts/install_script_agent7.sh)"
# ポート 6062 での競合を回避
echo "process_config.expvar_port: 6063" >> /etc/datadog-agent/datadog.yaml
echo "Datadog Agent is installed"
while [ -z \$DB_DRIVER_PORT ]; do
if [ -e "/tmp/driver-env.sh" ]; then
DB_DRIVER_PORT="\$(grep -i "CONF_UI_PORT" /tmp/driver-env.sh | cut -d'=' -f2)"
fi
echo "Waiting 2 seconds for DB_DRIVER_PORT"
sleep 2
done
echo "DB_DRIVER_PORT=\$DB_DRIVER_PORT"
# 構造化ストリーミングメトリクスを有効にし Spark インテグレーション用のコンフィギュレーションファイルを記述
# 他のオプションを spark.d/conf.yaml.example に含めるように変更します
echo "init_config:
instances:
- spark_url: http://\${DB_DRIVER_IP}:\${DB_DRIVER_PORT}
spark_cluster_mode: spark_driver_mode
cluster_name: \${DB_CLUSTER_NAME}
streaming_metrics: true
executor_level_metrics: true
logs:
- type: file
path: /databricks/driver/logs/*.log
source: spark
service: databricks
log_processing_rules:
- type: multi_line
name: new_log_start_with_date
pattern: \d{2,4}[\-\/]\d{2,4}[\-\/]\d{2,4}.*" > /etc/datadog-agent/conf.d/spark.d/spark.yaml
echo "Spark integration configured"
# datadog.yaml のログを有効にしてドライバーログを収集します
sed -i '/.*logs_enabled:.*/a logs_enabled: true' /etc/datadog-agent/datadog.yaml
fi
echo "Restart the agent"
sudo service datadog-agent restart
EOF
chmod a+x /tmp/start_datadog.sh
/tmp/start_datadog.sh >> /tmp/datadog_start.log 2>&1 & disown
Datadog Agent をドライバーノードとワーカーノードにインストールする
クラスターのドライバーノードとワーカーノードに Datadog Agent をインストールします。
#!/bin/bash
cat <<EOF > /tmp/start_datadog.sh
#!/bin/bash
date -u +"%Y-%m-%d %H:%M:%S UTC"
echo "Running on the driver? \$DB_IS_DRIVER"
echo "Driver ip: \$DB_DRIVER_IP"
DB_CLUSTER_NAME=$(echo "$DB_CLUSTER_NAME" | sed -e 's/ /_/g' -e "s/'/_/g")
if [[ \${DB_IS_DRIVER} = "TRUE" ]]; then
echo "Installing Datadog Agent on the driver (master node)."
# ドライバー用のホストタグを構成する
DD_TAGS="environment:\${DD_ENV}","databricks_cluster_id:\${DB_CLUSTER_ID}","databricks_cluster_name:\${DB_CLUSTER_NAME}","spark_host_ip:\${DB_DRIVER_IP}","spark_node:driver","databricks_instance_type:\${DB_INSTANCE_TYPE}","databricks_is_job_cluster:\${DB_IS_JOB_CLUSTER}"
# 最新の Datadog Agent 7 をドライバーノードとワーカーノードにインストールする
DD_INSTALL_ONLY=true \
DD_API_KEY=\$DD_API_KEY \
DD_HOST_TAGS=\$DD_TAGS \
DD_HOSTNAME="\$(hostname | xargs)" \
DD_SITE="\${DD_SITE:-datadoghq.com}" \
bash -c "\$(curl -L https://s3.amazonaws.com/dd-agent/scripts/install_script_agent7.sh)"
echo "Datadog Agent is installed"
while [ -z \$DB_DRIVER_PORT ]; do
if [ -e "/tmp/driver-env.sh" ]; then
DB_DRIVER_PORT="\$(grep -i "CONF_UI_PORT" /tmp/driver-env.sh | cut -d'=' -f2)"
fi
echo "Waiting 2 seconds for DB_DRIVER_PORT"
sleep 2
done
echo "DB_DRIVER_PORT=\$DB_DRIVER_PORT"
# 構造化ストリーミングメトリクスを有効にし Spark インテグレーション用のコンフィギュレーションファイルを記述
# spark.d/conf.yaml.example に他のオプションを含めるように変更する
echo "init_config:
instances:
- spark_url: http://\${DB_DRIVER_IP}:\${DB_DRIVER_PORT}
spark_cluster_mode: spark_driver_mode
cluster_name: \${DB_CLUSTER_NAME}
streaming_metrics: true
executor_level_metrics: true
logs:
- type: file
path: /databricks/driver/logs/*.log
source: spark
service: databricks
log_processing_rules:
- type: multi_line
name: new_log_start_with_date
pattern: \d{2,4}[\-\/]\d{2,4}[\-\/]\d{2,4}.*" > /etc/datadog-agent/conf.d/spark.d/spark.yaml
echo "Spark integration configured"
# ドライバーのログを収集するために datadog.yaml でログを有効にする
sed -i '/.*logs_enabled:.*/a logs_enabled: true' /etc/datadog-agent/datadog.yaml
else
echo "Installing Datadog Agent on the worker."
# ワーカー用のホストタグを構成する
DD_TAGS="environment:\${DD_ENV}","databricks_cluster_id:\${DB_CLUSTER_ID}","databricks_cluster_name:\${DB_CLUSTER_NAME}","spark_host_ip:\${SPARK_LOCAL_IP}","spark_node:worker","databricks_instance_type:\${DB_INSTANCE_TYPE}","databricks_is_job_cluster:\${DB_IS_JOB_CLUSTER}"
# 最新の Datadog Agent 7 をドライバーノードとワーカーノードにインストールする
# バージョン 7.40 以上で Agent が失敗しないように、datadog.yaml でホスト名を明確に構成する
# 変更については https://github.com/DataDog/datadog-agent/issues/14152 をご覧ください
DD_INSTALL_ONLY=true DD_API_KEY=\$DD_API_KEY DD_HOST_TAGS=\$DD_TAGS DD_HOSTNAME="\$(hostname | xargs)" bash -c "\$(curl -L https://s3.amazonaws.com/dd-agent/scripts/install_script_agent7.sh)"
echo "Datadog Agent is installed"
fi
# ポート 6062 での競合を回避
echo "process_config.expvar_port: 6063" >> /etc/datadog-agent/datadog.yaml
echo "Restart the agent"
sudo service datadog-agent restart
EOF
chmod a+x /tmp/start_datadog.sh
/tmp/start_datadog.sh >> /tmp/datadog_start.log 2>&1 & disown
収集データ
メトリクス
収集されたメトリクスのリストについては、Spark インテグレーションドキュメントを参照してください。
サービスチェック
収集されたサービスチェックのリストについては、Spark インテグレーションドキュメントを参照してください。
イベント
Databricks インテグレーションには、イベントは含まれません。
トラブルシューティング
Databricks Web ターミナルを有効にするか、Databricks ノートブックを使用することで、問題を自分でトラブルシューティングできます。有用なトラブルシューティング手順については、Agent のトラブルシューティングのドキュメントを参照してください。
ご不明な点は、Datadog のサポートチームまでお問合せください。
その他の参考資料
お役に立つドキュメント、リンクや記事: