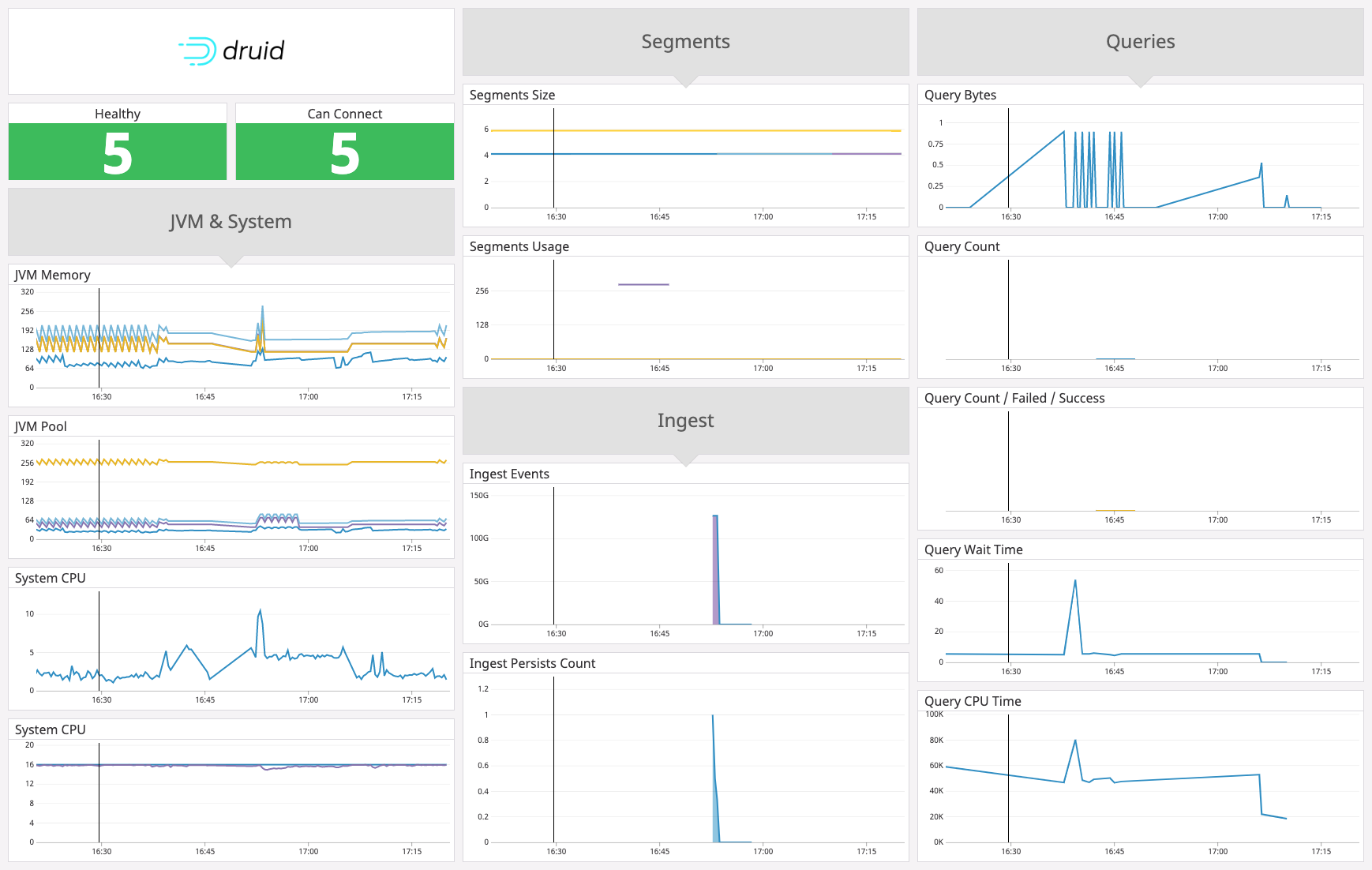
druid.coordinator.segment.count
(gauge) | Coordinator segment count.
Shown as segment |
druid.historical.segment.count
(gauge) | Historical segment count.
Shown as segment |
druid.ingest.events.buffered
(gauge) | Number of events queued in the EventReceiverFirehose's buffer.
Shown as event |
druid.ingest.events.duplicate
(count) | Number of events rejected because the events are duplicated.
Shown as event |
druid.ingest.events.messageGap
(gauge) | Time gap between the data time in event and current system time.
Shown as millisecond |
druid.ingest.events.processed
(count) | Number of events successfully processed per emission period.
Shown as event |
druid.ingest.events.thrownAway
(count) | Number of events rejected because they are outside the windowPeriod.
Shown as event |
druid.ingest.events.unparseable
(count) | Number of events rejected because the events are unparsable.
Shown as event |
druid.ingest.handoff.failed
(count) | Number of handoffs that failed. |
druid.ingest.kafka.avgLag
(gauge) | Average lag between the offsets consumed by the Kafka indexing tasks and latest offsets in Kafka brokers across all partitions. Minimum emission period for this metric is a Minute.
Shown as offset |
druid.ingest.kafka.lag
(gauge) | Total lag between the offsets consumed by the Kafka indexing tasks and latest offsets in Kafka brokers across all partitions. Minimum emission period for this metric is a Minute.
Shown as offset |
druid.ingest.kafka.maxLag
(gauge) | Max lag between the offsets consumed by the Kafka indexing tasks and latest offsets in Kafka brokers across all partitions. Minimum emission period for this metric is a Minute.
Shown as offset |
druid.ingest.merge.cpu
(gauge) | Cpu time in Nanoseconds spent on merging intermediate segments.
Shown as nanosecond |
druid.ingest.merge.time
(gauge) | Milliseconds spent merging intermediate segments.
Shown as millisecond |
druid.ingest.persists.backPressure
(gauge) | Milliseconds spent creating persist tasks and blocking waiting for them to finish.
Shown as millisecond |
druid.ingest.persists.count
(count) | Number of times persist occurred. |
druid.ingest.persists.cpu
(gauge) | Cpu time in Nanoseconds spent on doing intermediate persist.
Shown as nanosecond |
druid.ingest.persists.failed
(count) | Number of persists that failed. |
druid.ingest.persists.time
(gauge) | Milliseconds spent doing intermediate persist.
Shown as millisecond |
druid.ingest.rows.output
(count) | Number of Druid rows persisted.
Shown as row |
druid.jvm.bufferpool.capacity
(gauge) | Bufferpool capacity in bytes.
Shown as byte |
druid.jvm.bufferpool.count
(gauge) | Bufferpool count in bytes.
Shown as byte |
druid.jvm.bufferpool.used
(gauge) | Bufferpool used in bytes.
Shown as byte |
druid.jvm.gc.count
(count) | Garbage collection count. |
druid.jvm.gc.cpu
(gauge) | Cpu time in Nanoseconds spent on garbage collection.
Shown as nanosecond |
druid.jvm.mem.committed
(gauge) | Committed memory in bytes.
Shown as byte |
druid.jvm.mem.init
(gauge) | Initial memory in bytes.
Shown as byte |
druid.jvm.mem.max
(gauge) | Max memory in bytes.
Shown as byte |
druid.jvm.mem.used
(gauge) | Used memory in bytes.
Shown as byte |
druid.jvm.pool.committed
(gauge) | Committed pool in byte.
Shown as byte |
druid.jvm.pool.init
(gauge) | Initial pool in bytes.
Shown as byte |
druid.jvm.pool.max
(gauge) | Max pool in bytes.
Shown as byte |
druid.jvm.pool.used
(gauge) | Pool used in bytes.
Shown as byte |
druid.query.bytes
(count) | Number of bytes returned in query response.
Shown as byte |
druid.query.cache.delta.averageBytes
(count) | Delta average cache entry byte size.
Shown as byte |
druid.query.cache.delta.errors
(count) | Delta number of cache errors. |
druid.query.cache.delta.evictions
(count) | Delta number of cache evictions.
Shown as eviction |
druid.query.cache.delta.hitRate
(count) | Delta cache hit rate.
Shown as fraction |
druid.query.cache.delta.hits
(count) | Delta number of cache hits.
Shown as hit |
druid.query.cache.delta.misses
(count) | Delta number of cache misses.
Shown as miss |
druid.query.cache.delta.numEntries
(count) | Delta number of cache entries. |
druid.query.cache.delta.sizeBytes
(count) | Delta size in bytes of cache entries.
Shown as byte |
druid.query.cache.delta.timeouts
(count) | Delta number of cache timeouts. |
druid.query.cache.total.averageBytes
(gauge) | Total average cache entry byte size.
Shown as byte |
druid.query.cache.total.errors
(gauge) | Total number of cache errors. |
druid.query.cache.total.evictions
(gauge) | Total number of cache evictions.
Shown as eviction |
druid.query.cache.total.hitRate
(gauge) | Total cache hit rate.
Shown as fraction |
druid.query.cache.total.hits
(gauge) | Total number of cache hits.
Shown as hit |
druid.query.cache.total.misses
(gauge) | Total number of cache misses.
Shown as miss |
druid.query.cache.total.numEntries
(gauge) | Total number of cache entries. |
druid.query.cache.total.sizeBytes
(gauge) | Total size in bytes of cache entries.
Shown as byte |
druid.query.cache.total.timeouts
(gauge) | Total number of cache timeouts. |
druid.query.count
(count) | Number of total queries.
Shown as query |
druid.query.cpu.time
(gauge) | Microseconds of CPU time taken to complete a query.
Shown as microsecond |
druid.query.failed.count
(count) | Number of failed queries.
Shown as query |
druid.query.interrupted.count
(count) | Number of queries interrupted due to cancellation or timeout.
Shown as query |
druid.query.intervalChunk.time
(gauge) | Only emitted if interval chunking is enabled. Milliseconds required to query an interval chunk. This metric is deprecated and will be removed in the future because interval Chunking is deprecated. See Query Context.
Shown as millisecond |
druid.query.node.backpressure
(gauge) | Milliseconds that the channel to this process has spent suspended due to backpressure.
Shown as millisecond |
druid.query.node.bytes
(count) | Number of bytes returned from querying individual historical/realtime processes.
Shown as byte |
druid.query.node.time
(gauge) | Milliseconds taken to query individual historical/realtime processes.
Shown as millisecond |
druid.query.node.ttfb
(gauge) | Time to first byte. Milliseconds elapsed until Broker starts receiving the response from individual historical/realtime processes.
Shown as millisecond |
druid.query.segment.time
(gauge) | Milliseconds taken to query individual segment. Includes time to page in the segment from disk.
Shown as millisecond |
druid.query.segmentAndCache.time
(gauge) | Milliseconds taken to query individual segment or hit the cache (if it is enabled on the Historical process).
Shown as millisecond |
druid.query.success.count
(count) | Number of queries successfully processed.
Shown as query |
druid.query.time
(gauge) | Milliseconds taken to complete a query.
Shown as millisecond |
druid.query.wait.time
(gauge) | Milliseconds spent waiting for a segment to be scanned.
Shown as millisecond |
druid.segment.added.bytes
(count) | Size in bytes of new segments created.
Shown as byte |
druid.segment.assigned.count
(count) | Number of segments assigned to be loaded in the cluster.
Shown as segment |
druid.segment.cost.normalization
(count) | Used in cost balancing. The normalization of hosting segments. |
druid.segment.cost.normalized
(count) | Used in cost balancing. The normalized cost of hosting segments. |
druid.segment.cost.raw
(count) | Used in cost balancing. The raw cost of hosting segments. |
druid.segment.deleted.count
(count) | Number of segments dropped due to rules.
Shown as segment |
druid.segment.dropQueue.count
(gauge) | Number of segments to drop.
Shown as segment |
druid.segment.dropped.count
(count) | Number of segments dropped due to being overshadowed.
Shown as segment |
druid.segment.loadQueue.count
(gauge) | Number of segments to load.
Shown as segment |
druid.segment.loadQueue.failed
(gauge) | Number of segments that failed to load.
Shown as segment |
druid.segment.loadQueue.size
(gauge) | Size in bytes of segments to load.
Shown as byte |
druid.segment.max
(gauge) | Maximum byte limit available for segments.
Shown as byte |
druid.segment.moved.bytes
(count) | Size in bytes of segments moved/archived via the Move Task.
Shown as byte |
druid.segment.moved.count
(count) | Number of segments moved in the cluster.
Shown as segment |
druid.segment.nuked.bytes
(count) | Size in bytes of segments deleted via the Kill Task.
Shown as byte |
druid.segment.overShadowed.count
(gauge) | Number of overShadowed segments.
Shown as segment |
druid.segment.pendingDelete
(gauge) | On-disk size in bytes of segments that are waiting to be cleared out.
Shown as byte |
druid.segment.scan.pending
(gauge) | Number of segments in queue waiting to be scanned.
Shown as unit |
druid.segment.size
(gauge) | Size in bytes of available segments.
Shown as byte |
druid.segment.unavailable.count
(count) | Number of segments (not including replicas) left to load until segments that should be loaded in the cluster are available for queries.
Shown as segment |
druid.segment.underReplicated.count
(count) | Number of segments (including replicas) left to load until segments that should be loaded in the cluster are available for queries.
Shown as segment |
druid.segment.unneeded.count
(count) | Number of segments dropped due to being marked as unused.
Shown as segment |
druid.segment.used
(gauge) | Bytes used for served segments.
Shown as byte |
druid.segment.usedPercent
(gauge) | Percentage of space used by served segments.
Shown as fraction |
druid.service.health
(gauge) | 1 if the service is healthy, 0 otherwise |
druid.sys.cpu
(gauge) | CPU used.
Shown as percent |
druid.sys.disk.read.count
(count) | Reads from disk.
Shown as read |
druid.sys.disk.read.size
(count) | Bytes read from disk. Can we used to determine how much paging is occurring with regards to segments.
Shown as byte |
druid.sys.disk.write.count
(count) | Writes to disk.
Shown as write |
druid.sys.disk.write.size
(count) | Bytes written to disk. Can we used to determine how much paging is occurring with regards to segments.
Shown as byte |
druid.sys.fs.max
(gauge) | Filesystesm bytes max.
Shown as byte |
druid.sys.fs.used
(gauge) | Filesystem bytes used.
Shown as byte |
druid.sys.mem.max
(gauge) | Memory max.
Shown as byte |
druid.sys.mem.used
(gauge) | Memory used.
Shown as byte |
druid.sys.net.read.size
(count) | Bytes read from the network.
Shown as byte |
druid.sys.net.write.size
(count) | Bytes written to the network.
Shown as byte |
druid.sys.storage.used
(gauge) | Disk space used.
Shown as byte |
druid.sys.swap.free
(gauge) | Free swap in bytes.
Shown as byte |
druid.sys.swap.max
(gauge) | Max swap in bytes.
Shown as byte |
druid.sys.swap.pageIn
(gauge) | Paged in swap.
Shown as page |
druid.sys.swap.pageOut
(gauge) | Paged out swap.
Shown as page |
druid.task.failed.count
(count) | Number of failed tasks per emission period. This metric is only available if the TaskCountStatsMonitor module is included.
Shown as task |
druid.task.pending.count
(count) | Number of current pending tasks. This metric is only available if the TaskCountStatsMonitor module is included.
Shown as task |
druid.task.run.time
(gauge) | Milliseconds taken to run a task.
Shown as millisecond |
druid.task.running.count
(count) | Number of current running tasks. This metric is only available if the TaskCountStatsMonitor module is included.
Shown as task |
druid.task.success.count
(count) | Number of successful tasks per emission period. This metric is only available if the TaskCountStatsMonitor module is included.
Shown as task |
druid.task.waiting.count
(count) | Number of current waiting tasks. This metric is only available if the TaskCountStatsMonitor module is included.
Shown as task |