Versión de la integración3.2.0
Esta integración monitoriza tu plataforma de Cloudera Data a través del Datadog Agent, permitiéndote enviar métricas y checks de servicio sobre el estado de tus clústeres, hosts y roles de Cloudera Data Hub.
Configuración
Sigue las instrucciones a continuación para instalar y configurar este check para un Agent que se ejecuta en un host. Para entornos en contenedores, consulta las plantillas de integración de Autodiscovery para obtener orientación sobre la aplicación de estas instrucciones.
Instalación
El check de Cloudera está incluido en el paquete del Datadog Agent.
No es necesaria ninguna instalación adicional en tu servidor.
Configuración
Requisitos
El check de Cloudera requiere la versión 7 de Cloudera Manager.
Preparar Cloudera Manager
En la plataforma de Cloudera Data, ve a la consola de gestión y haz clic en la pestaña User Management (Gestión de usuarios).
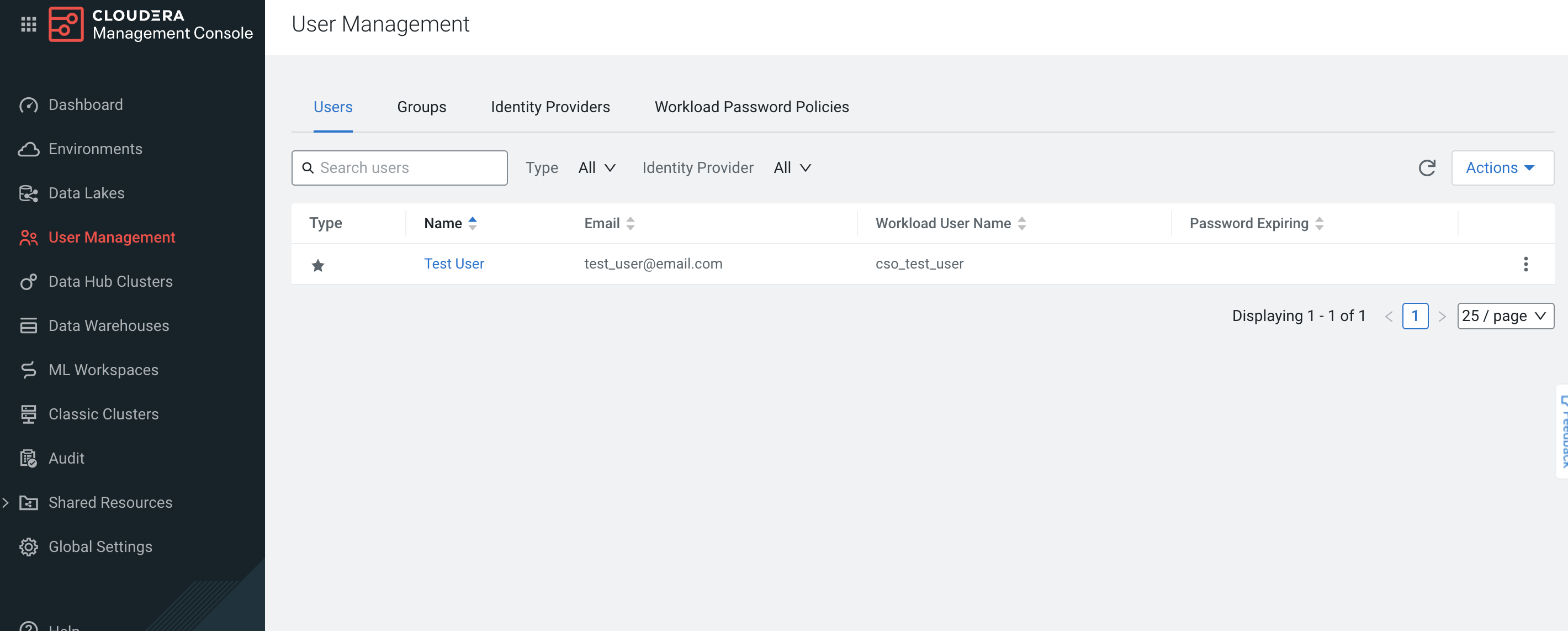
Haz clic en Actions (Acciones), luego en Create Machine User (Crear usuario de máquina) para crear el usuario de máquina que consulta el Cloudera Manager a través del Datadog Agent.
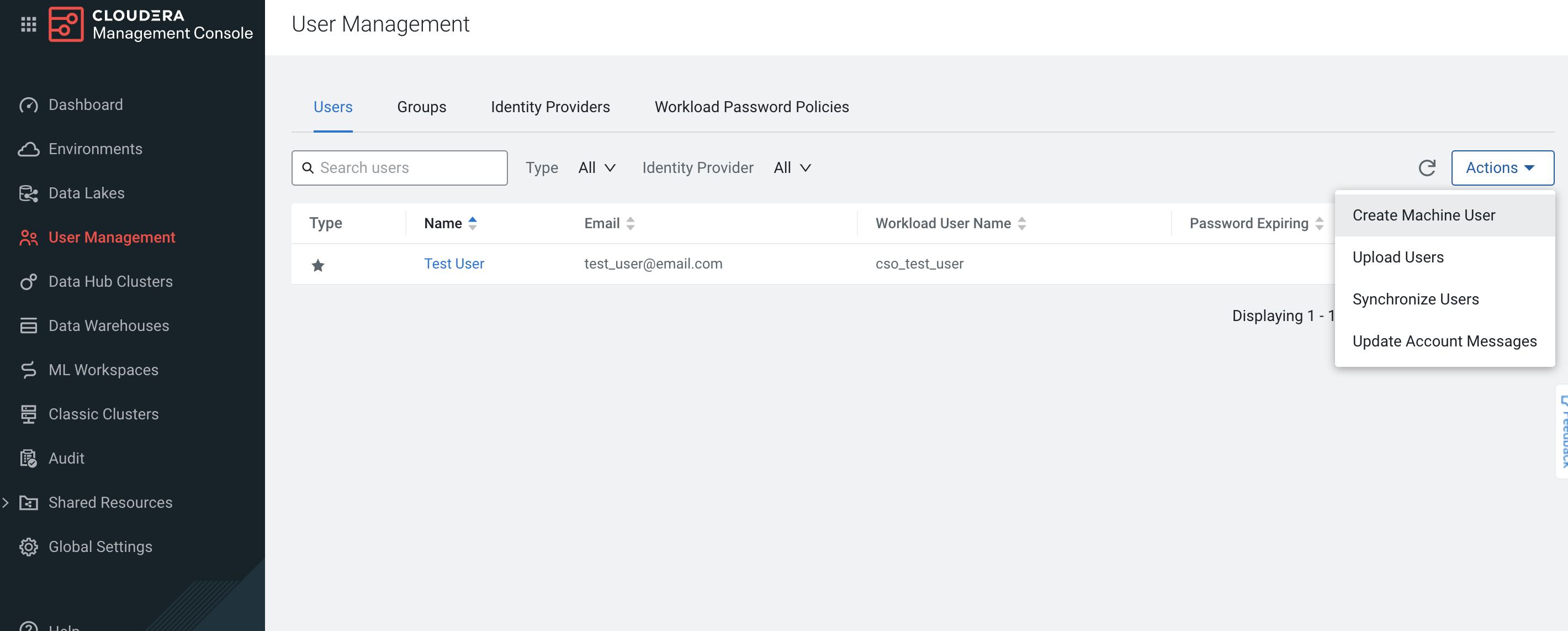
Si no se ha establecido la contraseña de la carga de trabajo, haz clic en Set Workload Password (Establecer la contraseña de la carga de trabajo) después de crear el usuario.
Host
Edita el archivo cloudera.d/conf.yaml, en la carpeta conf.d/ en la raíz de tu directorio de configuración del Agent para comenzar a recopilar tus datos de clúster y host de Cloudera. Ve el cloudera.d/conf.yaml de ejemplo para conocer todas las opciones disponibles de configuración.
Nota: La api_url debe contener la versión de la API al final.
init_config:
## @param workload_username - string - required
## The Workload username. This value can be found in the `User Management` tab of the Management
## Console in the `Workload User Name`.
#
workload_username: <WORKLOAD_USERNAME>
## @param workload_password - string - required
## The Workload password. This value can be found in the `User Management` tab of the Management
## Console in the `Workload Password`.
#
workload_password: <WORKLOAD_PASSWORD>
## Every instance is scheduled independently of the others.
#
instances:
## @param api_url - string - required
## The URL endpoint for the Cloudera Manager API. This can be found under the Endpoints tab for
## your Data Hub to monitor.
##
## Note: The version of the Cloudera Manager API needs to be appended at the end of the URL.
## For example, using v48 of the API for Data Hub `cluster_1` should result with a URL similar
## to the following:
## `https://cluster1.cloudera.site/cluster_1/cdp-proxy-api/cm-api/v48`
#
- api_url: <API_URL>
Reinicia el Agent para empezar a recopilar y enviar datos del clúster de Cloudera Data Hub a Datadog.
Contenedores
Para entornos en contenedores, consulta las plantillas de integración de Autodiscovery para obtener orientación sobre la aplicación de los parámetros que se indican a continuación.
| Parámetro | Valor |
|---|
<INTEGRATION_NAME> | cloudera |
<INIT_CONFIG> | {"workload_username": "<WORKLOAD_USERNAME>", 'workload_password": "<WORKLOAD_PASSWORD>"} |
<INSTANCE_CONFIG> | {"api_url": <API_URL>"} |
Detección de clústeres
Puedes configurar cómo se detectan tus clústeres con la opción de configuración clusters con los siguientes parámetros:
limit
: número máximo de elementos para Autodiscovery.
Valor por defecto: None (se procesarán todos los clústeres)
include
: asignación de claves de expresiones regulares y valores de configuración de componentes para Autodiscovery.
Valor por defecto: asignación vacía
exclude
: lista de expresiones regulares con los patrones de los componentes a excluir de Autodiscovery.
Valor por defecto: lista vacía
interval
: tiempo de validez en segundos de la última lista de clústeres obtenida a través del endpoint.
Valor por defecto: None (no se utiliza caché)
Ejemplos:
Proceso de un máximo de 5 clústeres con nombres que empiecen por my_cluster:
clusters:
limit: 5
include:
- 'my_cluster.*'
Proceso de un máximo de 20 clústeres y exclusión de aquellos cuyos nombres empiecen por tmp_:
clusters:
limit: 20
include:
- '.*'
exclude:
- 'tmp_.*'
Consultas personalizadas
Puedes configurar la integración de Cloudera para recopilar métricas personalizadas que no se recopilan por defecto ejecutando consultas de series temporales personalizadas. Estas consultas utilizan el lenguaje tsquery para recuperar datos de Cloudera Manager.
Ejemplo:
Recopila la tasa de recopilación de elementos no usados de la JVM y la memoria libre de la JVM con cloudera_jvm como una etiqueta personalizada:
custom_queries:
- query: select last(jvm_gc_rate) as jvm_gc_rate, last(jvm_free_memory) as jvm_free_memory
tags: cloudera_jvm
Nota: Estas consultas pueden aprovechar las expresiones de métrica, dando lugar a consultas como total_cpu_user + total_cpu_system, 1000 * jvm_gc_time_ms / jvm_gc_count y max(total_cpu_user). Cuando utilices expresiones de métrica, asegúrate de incluir también alias para las métricas, ya que de lo contrario los nombres de métrica podrían tener un formato incorrecto. Por ejemplo, SELECT last(jvm_gc_count) da como resultado la métrica cloudera.<CATEGORY>.last_jvm_gc_count. Puedes añadir un alias como en el siguiente ejemplo: SELECT last(jvm_gc_count) as jvm_gc_count para generar la métrica cloudera.<CATEGORY>.jvm_gc_count.
Validación
Ejecuta el subcomando de estado del Agent y busca cloudera en la sección Checks.
Datos recopilados
Métricas
Eventos
La integración de Cloudera recopila eventos que se emiten desde el endpoint /events de la API de Cloudera Manager. Los niveles de evento se asignan de la siguiente manera:
| Cloudera | Datadog |
|---|
UNKNOWN | error |
INFORMATIONAL | info |
IMPORTANT | info |
CRITICAL | error |
Checks de servicio
Solucionar problemas
Recopilación de métricas de integraciones de Datadog en hosts de Cloudera
Para instalar el Datadog Agent en un host de Cloudera, asegúrate de que el grupo de seguridad asociado al host permite el acceso SSH.
A continuación, deberás utilizar el usuario raíz cloudbreak cuando accedas al host con la clave SSH generada durante la creación del entorno:
sudo ssh -i "/path/to/key.pem" cloudbreak@<HOST_IP_ADDRESS>
El nombre de usuario y la contraseña de la carga de trabajo pueden utilizarse para acceder a hosts de Cloudera a través de SSH, aunque sólo el usuario cloudbreak puede instalar el Datadog Agent.
Intentar utilizar cualquier usuario que no sea cloudbreak puede dar lugar al siguiente error:
<NON_CLOUDBREAK_USER> is not allowed to run sudo on <CLOUDERA_HOSTNAME>. This incident will be reported.
Errores de configuración al recopilar métricas de Datadog
Si ves algo similar a lo siguiente en el estado del Agent al recopilar métricas de tu host de Cloudera:
Config Errors
==============
zk
--
open /etc/datadog-agent/conf.d/zk.d/conf.yaml: permission denied
Debes cambiar la propiedad de conf.yaml a dd-agent:
[cloudbreak@<CLOUDERA_HOSTNAME> ~]$ sudo chown -R dd-agent:dd-agent /etc/datadog-agent/conf.d/zk.d/conf.yaml
¿Necesitas ayuda? Ponte en contacto con el equipo de asistencia de Datadog.
Referencias adicionales
Más enlaces, artículos y documentación útiles: