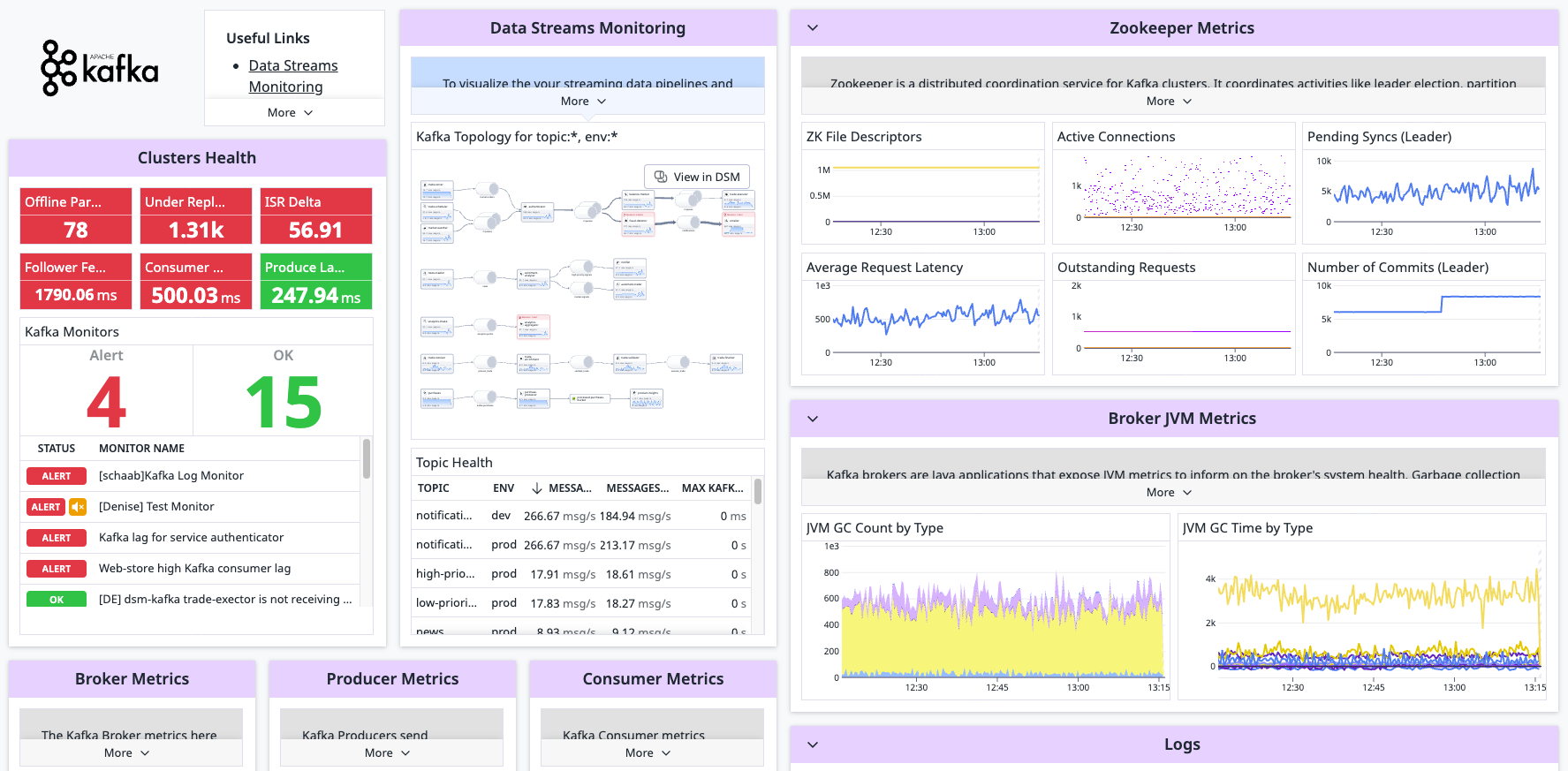
Présentation
Associez Kafka à Datadog pour :
- Visualiser les performances de votre cluster en temps réel
- Corréler les performances de Kafka avec le reste de vos applications
Ce check prévoit une limite de 350 métriques par instance. Le nombre de métriques renvoyées est indiqué dans la page d’information. Choisissez des métriques pertinentes en modifiant la configuration ci-dessous. Pour découvrir comment personnaliser la liste des métriques à recueillir, consultez la documentation relative aux checks JMX afin d’obtenir des instructions détaillées.
Pour recueillir les métriques relatives aux consommateurs de Kafka, consultez la section check kafka_consumer.
Remarque : cet exemple de configuration de l’intégration ne fonctionne que pour Kafka 0.8.2 ou les versions ultérieures. Si vous utilisez une version antérieure, consultez les exemples de fichier pour les versions 5.2.x de l’Agent.
Configuration
Installation
Le check Kafka de l’Agent est inclus avec le paquet de l’Agent Datadog : vous n’avez donc rien d’autre à installer sur vos nœuds Kafka.
Le check recueille des métriques à partir de JMX avec JMXFetch. Pour que l’Agent puisse exécuter JMXFetch, chaque nœud Kafka nécessite une JVM. Il peut s’agir de la même JVM que celle utilisée par Kafka.
Remarque : Il n’est pas possible d’utiliser le check Kafka avec Managed Streaming for Apache Kafka (Amazon MSK). Utilisez plutôt l’intégration Amazon MSK.
Configuration
Host
Pour configurer ce check lorsque l’Agent est exécuté sur un host :
Collecte de métriques
Modifiez le fichier kafka.d/conf.yaml dans le dossier conf.d/ à la racine du répertoire de configuration de votre Agent. Les noms des beans de Kafka dépendent de la version précise de Kafka que vous exécutez. Utilisez le fichier d’exemple de configuration fourni avec l’Agent pour vous guider. Il s’agit de la configuration la plus récente. Remarque : la version de l’Agent citée dans l’exemple peut correspondre à une version plus récente que celle que vous avez installée.
Redémarrez l’Agent.
Collecte de logs
Disponible à partir des versions > 6.0 de l’Agent
Kafka utilise le logger log4j par défaut. Pour activer la journalisation dans un fichier et personnaliser le format, modifiez le fichier log4j.properties :
# Set root logger level to INFO and its only appender to R
log4j.rootLogger=INFO, R
log4j.appender.R.File=/var/log/kafka/server.log
log4j.appender.R.layout=org.apache.log4j.PatternLayout
log4j.appender.R.layout.ConversionPattern=%d{yyyy-MM-dd HH:mm:ss} %-5p %c{1}:%L - %m%n
Par défaut, le pipeline d’intégration de Datadog prend en charge les expressions de conversion suivantes :
%d{yyyy-MM-dd HH:mm:ss} %-5p %c{1}:%L - %m%n
%d [%t] %-5p %c - %m%n
%r [%t] %p %c %x - %m%n
[%d] %p %m (%c)%n
Dupliquez et modifiez le pipeline d’intégration si vous utilisez un autre format.
La collecte de logs est désactivée par défaut dans l’Agent Datadog. Vous devez l’activer dans datadog.yaml :
Ajoutez le bloc de configuration suivant à votre fichier kafka.d/conf.yaml. Modifiez les valeurs des paramètres path et service en fonction de votre environnement. Consultez le fichier d’exemple kafka.d/conf.yaml pour découvrir toutes les options de configuration disponibles.
logs:
- type: file
path: /var/log/kafka/server.log
source: kafka
service: myapp
#To handle multi line that starts with yyyy-mm-dd use the following pattern
#log_processing_rules:
# - type: multi_line
# name: log_start_with_date
# pattern: \d{4}\-(0?[1-9]|1[012])\-(0?[1-9]|[12][0-9]|3[01])
Redémarrez l’Agent.
Environnement conteneurisé
Collecte de métriques
Pour les environnements conteneurisés, consultez le guide Autodiscovery avec JMX.
Collecte de logs
Disponible à partir des versions > 6.0 de l’Agent
La collecte des logs est désactivée par défaut dans l’Agent Datadog. Pour l’activer, consultez la section Collecte de logs Kubernetes.
| Paramètre | Valeur |
|---|
<CONFIG_LOG> | {"source": "kafka", "service": "<NOM_SERVICE>"} |
Validation
Lancez la sous-commande status de l’Agent et cherchez kafka dans la section JMXFetch :
========
JMXFetch
========
Initialized checks
==================
kafka
instance_name : kafka-localhost-9999
message :
metric_count : 46
service_check_count : 0
status : OK
Données collectées
Métriques
Événements
Le check Kafka n’inclut aucun événement.
Checks de service
kafka.can_connect
Renvoie CRITICAL si l’Agent n’est pas capable de se connecter à l’instance Kafka qu’il surveille et d’y recueillir des métriques. Si ce n’est pas le cas, renvoie OK.
Statuses: ok, critical
Dépannage
Pour aller plus loin
Intégration Kafka Consumer
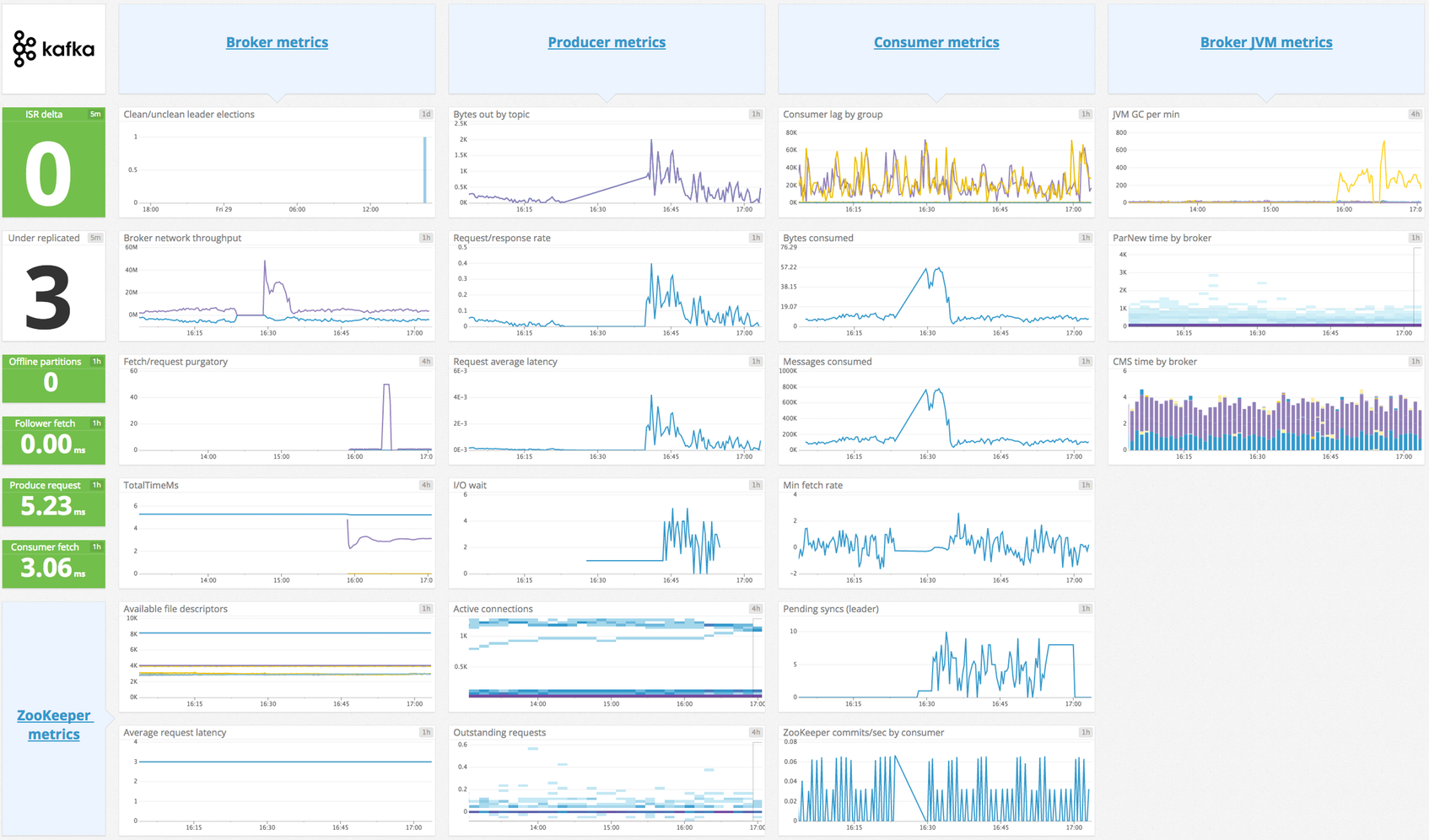
Présentation
Ce check d’Agent recueille uniquement les métriques pour les décalages de messages. Si vous souhaitez recueillir les métriques JMX sur des agents Kafka ou des consommateurs/producteurs basés sur Java, consultez le check Kafka.
Ce check récupère les décalages records des agents Kafka, les décalages des consommateurs qui sont stockés dans Kafka ou Zookeeper (pour ceux qui l’utilisent encore) et le retard des consommateurs calculé (qui correspond à la différence entre le décalage des agents et celui des consommateurs).
Remarque : cette intégration veille à ce que les décalages des consommateurs soient vérifiés avant les décalages des agents. Avec un tel procédé, dans le pire des cas, le retard des consommateurs est légèrement exagéré. L’approche inverse peut minimiser le retard des consommateurs, à tel point qu’il est possible d’atteindre des valeurs négatives. De telles valeurs apparaissent uniquement pour l’un des pires scénarios, à savoir lorsque des messages sont ignorés.
Configuration
Installation
Le check Kafka Consumer de l’Agent est inclus avec le package de l’Agent Datadog : vous n’avez donc rien d’autre à installer sur vos nœuds Kafka.
Configuration
Host
Pour configurer ce check lorsque l’Agent est exécuté sur un host :
Collecte de métriques
Modifiez le fichier kafka_consumer.d/conf.yaml dans le dossier conf.d/ à la racine du répertoire de configuration de votre Agent. Consultez le fichier d’exemple kafka_consumer.d/conf.yaml pour découvrir toutes les options de configuration disponibles.
Redémarrez l’Agent.
Collecte de logs
Ce check ne recueille aucun log supplémentaire. Pour recueillir des logs à partir de vos agents Kafka, consultez les instructions de collecte de logs pour Kafka.
Environnement conteneurisé
Pour les environnements conteneurisés, consultez le guide Autodiscovery avec JMX.
Validation
Lancez la sous-commande status de l’Agent et cherchez kafka_consumer dans la section Checks.
Données collectées
Métriques
Événements
consumer_lag :
L’Agent Datadog génère un événement lorsque la valeur de la métrique consumer_lag descend en dessous de 0, et lui ajoute les tags topic, partition et consumer_group.
Checks de service
Le check Kafka-consumer n’inclut aucun check de service.
Dépannage
Authentification à l’aide de la GSSAPI Kerberos
Selon la configuration Kerberos de votre cluster Kafka, vous devrez peut-être configurer les éléments suivants :
- Le client Kafka permettant à l’Agent Datadog de se connecter à l’agent Kafka. Le client Kafka doit être ajouté en tant que principal Kerberos, puis ajouté à un keytab Kerberos. Le client Kafka doit également posséder un ticket Kerberos valide.
- Le certificat TLS permettant d’authentifier une connexion sécurisée à l’agent Kafka.
- Si le keystore JKS est utilisé, un certificat doit être exporté à partir de ce keystore et le chemin du fichier doit être configuré avec les options
tls_cert et/ou tls_ca_cert applicables. - Si une clé privée est requise pour authentifier le certificat, elle doit être configurée avec l’option
tls_private_key. Le mot de passe de la clé privée doit être configuré avec l’option tls_private_key_password, le cas échéant.
- La variable d’environnement
KRB5_CLIENT_KTNAME pointant vers l’emplacement du keytab Kerberos du client Kafka, si son emplacement ne correspond pas au chemin par défaut (par exemple, KRB5_CLIENT_KTNAME=/etc/krb5.keytab). - La variable d’environnement
KRB5CCNAME pointant vers le cache du ticket des identifiants Kerberos du client Kafka, si son emplacement ne correspond pas au chemin par défaut (par exemple, KRB5CCNAME=/tmp/krb5cc_xxx). - Si l’Agent Datadog ne peut pas accéder aux variables d’environnement, définissez-les dans un fichier de remplacement de la configuration du service de l’Agent Datadog pour votre système d’exploitation. La procédure de modification du fichier d’unité du service de l’Agent Datadog peut varier selon la version du système d’exploitation Linux utilisée. Par exemple, dans un environnement Linux
systemd :
Exemple de Systemd Linux
- Configurez les variables d’environnement dans un fichier d’environnement.
Par exemple :
/chemin/vers/fichier/environnement
KRB5_CLIENT_KTNAME=/etc/krb5.keytab
KRB5CCNAME=/tmp/krb5cc_xxx
Créez un fichier de remplacement de la configuration du service de l’Agent Datadog : sudo systemctl edit datadog-agent.service.
Configurez ce qui suit dans le fichier de remplacement :
[Service]
EnvironmentFile=/path/to/environment/file
- Exécutez les commandes suivantes pour recharger le daemon systemd, le service datadog-agent et l’Agent Datadog :
sudo systemctl daemon-reload
sudo systemctl restart datadog-agent.service
sudo service datadog-agent restart
Pour aller plus loin