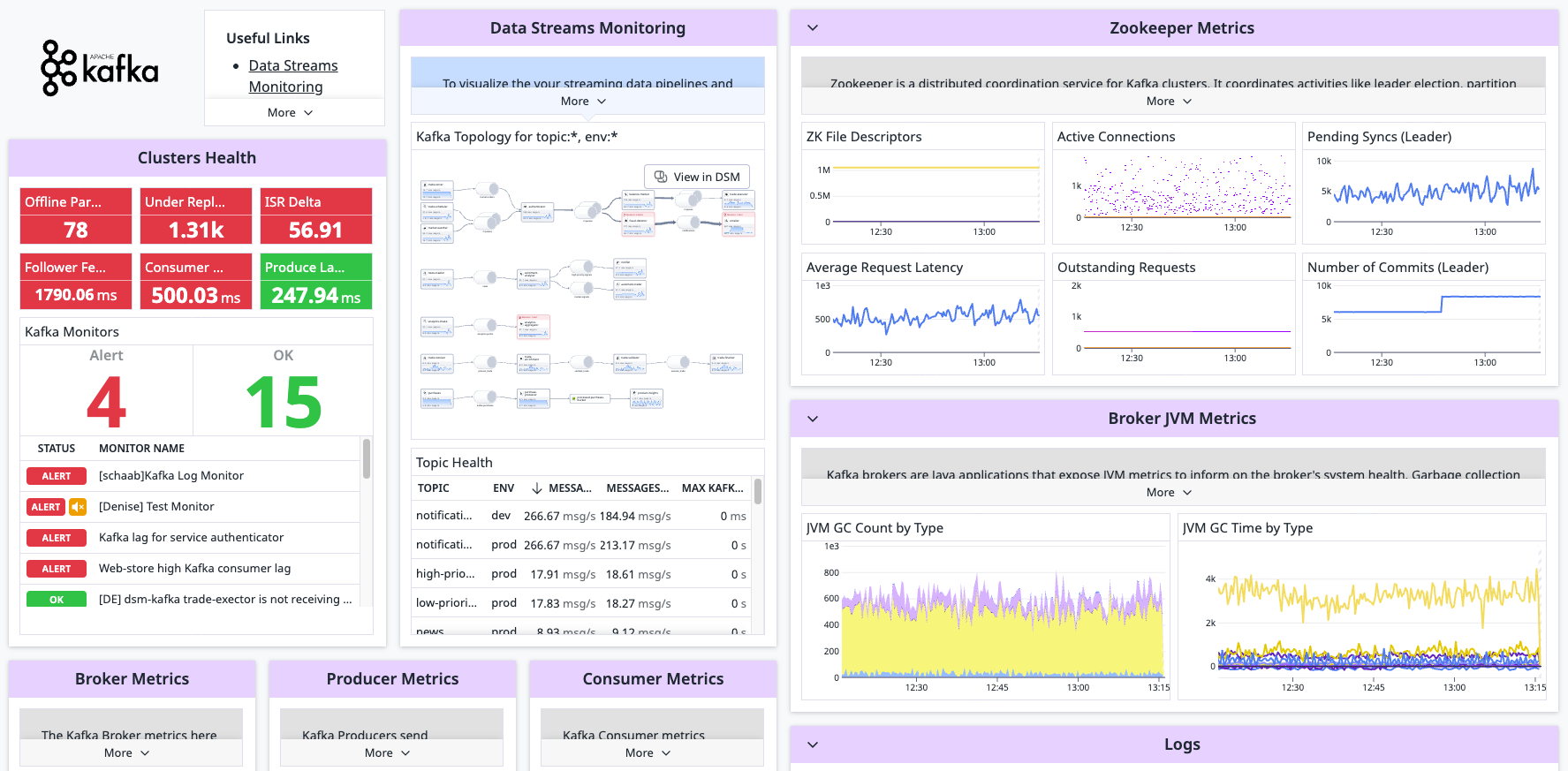
概要
収集した Kafka ブローカーのメトリクスを表示し、Kafka クラスターの健全性とパフォーマンスを 360 度リアルタイムで確認できます。このインテグレーションにより、Kafka デプロイメントからメトリクスとログを収集し、Kafka スタックのパフォーマンスに関するテレメトリーデータの可視化やアラートの発行が可能です。
注:
- このチェックでは、インスタンスごとに 350 メトリクスの制限があります。返されたメトリクスの数は、Agent のステータス出力に表示されます。以下の構成を編集して、関心のあるメトリクスを指定します。収集するメトリクスのカスタマイズの詳細については、JMX チェックのドキュメントを参照してください。
- このインテグレーションに付属するサンプル構成は、Kafka バージョン 0.8.2 以降でのみ動作します。
それ以前のバージョンを使用している場合は、Agent v5.2.x リリースサンプルファイルを参照してください。
- Kafka コンシューマーメトリクスを収集する方法については、kafka_consumer チェックを参照してください。
Kafka インテグレーションを強化する手段として、Data Streams Monitoring の利用を検討してください。このソリューションではパイプラインを可視化し、ラグ (遅延) を追跡できるため、ボトルネックの特定と解消に役立ちます。
セットアップ
インストール
Agent の Kafka チェックは Datadog Agent パッケージに含まれています。Kafka ノードに追加でインストールする必要はありません。
チェックは、JMXFetch を使用して JMX からメトリクスを収集します。Agent が JMXFetch を実行できるように、各 kafka ノードで JVM が必要です。Kafka が使用しているのと同じ JVM を使用することができます。
注: Kafka チェックは Managed Streaming for Apache Kafka (Amazon MSK) と共に使用することはできません。代わりに Amazon MSK インテグレーションを使用してください。
構成
ホスト
ホストで実行中の Agent に対してこのチェックを構成するには
メトリクスの収集
Agent のコンフィギュレーションディレクトリのルートにある conf.d/ フォルダーの kafka.d/conf.yaml ファイルを編集します。Kafka Bean 名は、実行している Kafka のバージョンに依存します。Agent と一緒にパッケージ化されているサンプルコンフィギュレーションファイルは最新の構成なので、これをベースとして使用してください。注: サンプル内の Agent バージョンは、インストールされている Agent のバージョンより新しいバージョンである場合があります。
Agent を再起動します。
ログ収集
Agent バージョン 6.0 以降で利用可能
Kafka はデフォルトで log4j ロガーを使用します。ファイルへのログ記録をアクティブにし、フォーマットをカスタマイズするには、log4j.properties ファイルを編集します。
# Set root logger level to INFO and its only appender to R
log4j.rootLogger=INFO, R
log4j.appender.R.File=/var/log/kafka/server.log
log4j.appender.R.layout=org.apache.log4j.PatternLayout
log4j.appender.R.layout.ConversionPattern=%d{yyyy-MM-dd HH:mm:ss} %-5p %c{1}:%L - %m%n
Datadog のインテグレーションパイプラインは、デフォルトで、次の変換パターンをサポートします。
%d{yyyy-MM-dd HH:mm:ss} %-5p %c{1}:%L - %m%n
%d [%t] %-5p %c - %m%n
%r [%t] %p %c %x - %m%n
[%d] %p %m (%c)%n
フォーマットが異なる場合は、インテグレーションパイプラインを複製して編集してください。
Datadog Agent で、ログの収集はデフォルトで無効になっています。以下のように、datadog.yaml ファイルでこれを有効にします。
次のコンフィギュレーションブロックを kafka.d/conf.yaml ファイルに追加します。環境に基づいて、path パラメーターと service パラメーターの値を変更してください。使用可能なすべてのコンフィギュレーションオプションの詳細については、サンプル kafka.d/conf.yaml を参照してください。
logs:
- type: file
path: /var/log/kafka/server.log
source: kafka
service: myapp
#To handle multi line that starts with yyyy-mm-dd use the following pattern
#log_processing_rules:
# - type: multi_line
# name: log_start_with_date
# pattern: \d{4}\-(0?[1-9]|1[012])\-(0?[1-9]|[12][0-9]|3[01])
Agent を再起動します。
コンテナ化
メトリクスの収集
コンテナ環境の場合は、JMX を使用したオートディスカバリーのガイドを参照してください。
ログ収集
Agent バージョン 6.0 以降で利用可能
Datadog Agent で、ログの収集はデフォルトで無効になっています。有効にする方法については、Kubernetes ログ収集を参照してください。
| パラメーター | 値 |
|---|
<LOG_CONFIG> | {"source": "kafka", "service": "<サービス名>"} |
検証
Agent の status サブコマンドを実行し、JMXFetch セクションの kafka を探します。
========
JMXFetch
========
Initialized checks
==================
kafka
instance_name : kafka-localhost-9999
message :
metric_count : 46
service_check_count : 0
status : OK
収集データ
メトリクス
イベント
Kafka チェックには、イベントは含まれません。
サービスチェック
kafka.can_connect
Agent が監視対象の Kafka インスタンスに接続できず、メトリクスを収集できない場合は、CRITICAL を返します。それ以外の場合は、OK を返します。
Statuses: ok, クリティカル
トラブルシューティング
その他の参考資料
Kafka コンシューマーインテグレーション
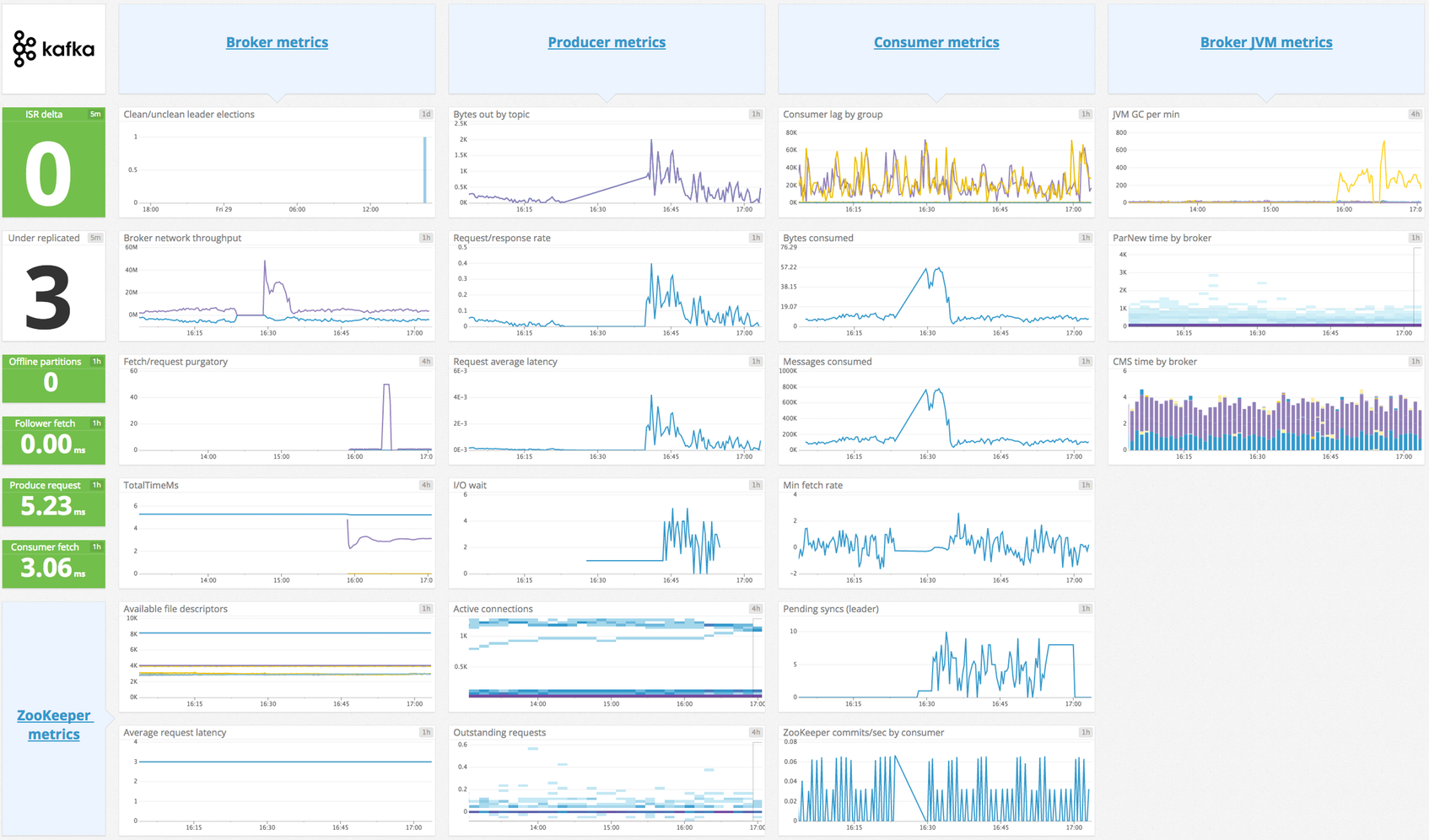
概要
この Agent インテグレーションは、Kafka コンシューマーからメッセージオフセットのメトリクスを収集します。このチェックでは、Kafka ブローカーからハイウォーターオフセットを取得し、Kafka (旧式のコンシューマーの場合は Zookeeper) に保存されているコンシューマーオフセットを取得して、ブローカーオフセットとコンシューマーオフセットの差であるコンシューマーラグを計算します。
注:
- このインテグレーションでは、ブローカーオフセットより先にコンシューマーオフセットをチェックするよう保証されています。そのため最悪の場合でも、コンシューマーラグがわずかに過大評価される程度で済みます。これらのオフセットを逆の順序でチェックすると、コンシューマーラグが負の値になるまで過小評価される可能性があり、これは通常メッセージがスキップされていることを示す深刻なシナリオです。
- Kafka ブローカーや Java ベースのコンシューマー/プロデューサーから JMX メトリクスを収集したい場合は、Kafka Broker インテグレーションを参照してください。
セットアップ
インストール
Agent の Kafka コンシューマーチェックは、Datadog Agent パッケージに含まれています。Kafka ノードに追加インストールする必要はありません。
構成
ホスト
Kafka コンシューマーが動作しているホスト上で Agent を実行している場合、このチェックを構成するには以下の手順に従います。
メトリクスの収集
Agent のコンフィギュレーションディレクトリのルートにある conf.d/ フォルダーの kafka_consumer.d/conf.yaml ファイルを編集します。使用可能なすべてのコンフィギュレーションオプションの詳細については、サンプル kafka_consumer.d/conf.yaml を参照してください。
Agent を再起動します。
ログ収集
このチェックは、その他のログを収集しません。Kafka ブローカーからログを収集するには、Kafka のログコレクション手順をご参照ください。
コンテナ化
コンテナ環境の場合は、オートディスカバリーのインテグレーションテンプレートのガイドを参照して、次のパラメーターを適用してください。
メトリクスの収集
| パラメーター | 値 |
|---|
<INTEGRATION_NAME> | kafka_consumer |
<INIT_CONFIG> | 空白または {} |
<INSTANCE_CONFIG> | {"kafka_connect_str": <KAFKA_CONNECT_STR>}
例: {"kafka_connect_str": "server:9092"} |
ログ収集
このチェックは、その他のログを収集しません。Kafka ブローカーからログを収集するには、Kafka のログコレクション手順をご参照ください。
検証
Agent の status サブコマンドを実行し、Checks セクションで kafka_consumer を探します。
収集データ
メトリクス
イベント
consumer_lag:
Datadog Agent は、consumer_lag メトリクスの値が 0 未満になると、topic、partition、および consumer_group のタグを付けてイベントを送信します。
サービスチェック
Kafka コンシューマーチェックには、サービスのチェック機能は含まれません。
トラブルシューティング
Kerberos GSSAPI 認証
Kafka クラスターの Kerberos 設定によっては、以下の構成が必要になる場合があります。
- Datadog Agent が Kafka ブローカーに接続するために構成された Kafka クライアント。Kafka クライアントは、Kerberos プリンシパルとして追加し、Kerberos keytab に追加する必要があります。また、Kafka クライアントには、有効な Kerberos チケットが必要です。
- Kafka ブローカーとのセキュアな接続を認証するための TLS 証明書。
- JKS keystore を使用する場合、証明書は keystore からエクスポートする必要があり、ファイルパスは適切な
tls_cert および tls_ca_cert オプションで構成される必要があります。 - 証明書を認証するために秘密鍵が必要な場合、
tls_private_key オプションで秘密鍵を構成する必要があります。また、秘密鍵のパスワードは tls_private_key_password オプションで構成する必要があります。
- Kafka クライアントの Kerberos keytab の場所がデフォルトのパスと異なる場合は、その場所を指す
KRB5_CLIENT_KTNAME 環境変数 (例: KRB5_CLIENT_KTNAME=/etc/krb5.keytab) - Kafka クライアントの Kerberos 資格情報チケットキャッシュがデフォルトのパスと異なる場合は、そのキャッシュを指す
KRB5CCNAME 環境変数 (例: KRB5CCNAME=/tmp/krb5cc_xxx) - Datadog Agent が環境変数にアクセスできない場合は、オペレーティングシステム用の Datadog Agent サービス構成オーバーライドファイルで環境変数を構成してください。Datadog Agent のサービスユニットファイルを変更する手順は、Linux オペレーティングシステムによって異なる場合があります。例えば、Linux の
systemd 環境では、以下のようになります。
Linux Systemd の例
- 環境ファイルで環境変数を構成します。
例:
/path/to/environment/file
KRB5_CLIENT_KTNAME=/etc/krb5.keytab
KRB5CCNAME=/tmp/krb5cc_xxx
Datadog Agent サービス構成オーバーライドファイル sudo systemctl edit datadog-agent.service を作成します。
オーバーライドファイルで以下のように構成します。
[Service]
EnvironmentFile=/path/to/environment/file
- 以下のコマンドを実行して、systemd デーモン、datadog-agent サービス、および Datadog Agent を再ロードします。
sudo systemctl daemon-reload
sudo systemctl restart datadog-agent.service
sudo service datadog-agent restart
その他の参考資料