Versión de la integración5.6.0
Este check monitoriza Snowflake a través del Datadog Agent. Snowflake es un almacén de datos analíticos SaaS y se ejecuta completamente en la infraestructura de la nube.
Esta integración monitoriza el uso de crédito, la facturación, el almacenamiento, las métricas de consulta y más.
Nota: Las métricas se recopilan mediante consultas a Snowflake. Las consultas realizadas mediante la integración de Datadog se facturan a través de Snowflake.
Configuración
Sigue las instrucciones a continuación para instalar y configurar este check para un Agent que se ejecuta en un host.
Instalación
El check de Snowflake está incluido en el paquete del Datadog Agent.
Nota: El check de Snowflake no está disponible en el Datadog Agent v6 con Python 2. Para usar Snowflake en el Agent v6, consulta Usar Python 3 con el Datadog Agent v6 o actualiza al Agent v7.
Configuración
Snowflake recomienda otorgar permisos a un rol alternativo como `SYSADMIN`. Lee más sobre cómo controlar el
rol ACCOUNTADMIN para obtener más información.
Crea un rol y un usuario específicos de Datadog para monitorizar Snowflake. En Snowflake, ejecuta lo siguiente para crear un rol personalizado con acceso al esquema ACCOUNT_USAGE.
Nota: Por defecto, esta integración monitoriza la base de datos SNOWFLAKE y el esquema ACCOUNT_USAGE. Consulta “Recopilación de datos de la organización” para obtener información sobre cómo monitorizar el esquema ORGANIZATION_USAGE.
Esta base de datos está disponible por defecto y solo la pueden ver los usuarios con el rol ACCOUNTADMIN o cualquier rol otorgado por el ACCOUNTADMIN.
use role ACCOUNTADMIN;
grant imported privileges on database snowflake to role SYSADMIN;
use role SYSADMIN;
Como alternativa, puedes crear un rol personalizado DATADOG con acceso a ACCOUNT_USAGE.
-- Crea un nuevo rol destinado a monitorizar el uso de Snowflake.
create role DATADOG;
-- Concede privilegios en la base de datos SNOWFLAKE al nuevo rol.
grant imported privileges on database SNOWFLAKE to role DATADOG;
-- Concede el uso de tu almacén predeterminado al rol DATADOG.
grant usage on warehouse <WAREHOUSE> to role DATADOG;
-- Crea un usuario; omite este paso si estás utilizando un usuario existente.
create user DATADOG_USER
LOGIN_NAME = DATADOG_USER
password = '<PASSWORD>'
default_warehouse = <WAREHOUSE>
default_role = DATADOG
default_namespace = SNOWFLAKE.ACCOUNT_USAGE;
-- Concede el rol de monitor al usuario.
grant role DATADOG to user <USER>;
Edita el archivo snowflake.d/conf.yaml, en la carpeta conf.d/ en la raíz del directorio de configuración de tu Agent para comenzar a recopilar los datos de rendimiento de Snowflake. Consulta el ejemplo snowflake.d/conf.yaml para conocer todas las opciones de configuración disponibles.
## @param account - string - required
## Name of your account (provided by Snowflake), including the platform and region if applicable.
## For more information on Snowflake account names,
## see https://docs.snowflake.com/en/user-guide/connecting.html#your-snowflake-account-name
#
- account: <ORG_NAME>-<ACCOUNT_NAME>
## @param username - string - required
## Login name for the user.
#
username: <USER>
## @param password - string - required
## Password for the user
#
password: <PASSWORD>
## @param role - string - required
## Name of the role to use.
##
## By default, the SNOWFLAKE database is only accessible by the ACCOUNTADMIN role. Snowflake recommends
## configuring a role specific for monitoring:
## https://docs.snowflake.com/en/sql-reference/account-usage.html#enabling-account-usage-for-other-roles
#
role: <ROLE>
## @param min_collection_interval - number - optional - default: 15
## This changes the collection interval of the check. For more information, see:
## https://docs.datadoghq.com/developers/write_agent_check/#collection-interval
##
## NOTE: Most Snowflake ACCOUNT_USAGE views are populated on an hourly basis,
## so to minimize unnecessary queries, set the `min_collection_interval` to 1 hour.
#
min_collection_interval: 3600
# @param disable_generic_tags - boolean - optional - default: false
# Generic tags such as `cluster` will be replaced by <integration_name>_cluster to avoid
# getting mixed with other integration tags.
# disable_generic_tags: true
In the default `conf.yaml`, the
min_collection_interval is 1 hour.
Snowflake metrics are aggregated by day, you can increase the interval to reduce the number of queries.
Note: Snowflake ACCOUNT_USAGE views have a
known latency of 45 minutes to 3 hours.
Reinicia el Agent.
Recopilación de datos de la organización
Por defecto, esta integración monitoriza el esquema ACCOUNT_USAGE, pero se puede configurar para monitorizar métricas a nivel de la organización.
Para recopilar métricas de la organización, cambia el campo del esquema a ORGANIZATION_USAGE y aumenta min_collection_interval a 43200 en la configuración de la integración. Esto reduce el número de consultas a Snowflake, ya que la mayoría de las consultas de la organización tienen una latencia de hasta 24 horas.
Nota: Para monitorizar métricas de organización, tu user debe tener el rol ORGADMIN.
- schema: ORGANIZATION_USAGE
min_collection_interval: 43200
De forma predeterminada, solo se habilitan algunas métricas de la organización. Para recopilar todas las métricas de la organización disponibles, utiliza la opción de configuración metric_groups:
metric_groups:
- snowflake.organization.warehouse
- snowflake.organization.currency
- snowflake.organization.credit
- snowflake.organization.storage
- snowflake.organization.contracts
- snowflake.organization.balance
- snowflake.organization.rate
- snowflake.organization.data_transfer
Además, puedes monitorizar las métricas de la cuenta y de la organización al mismo tiempo:
instances:
- account: example-inc
username: DATADOG_ORG_ADMIN
password: '<PASSWORD>'
role: SYSADMIN
schema: ORGANIZATION_USAGE
database: SNOWFLAKE
min_collection_interval: 43200
- account: example-inc
username: DATADOG_ACCOUNT_ADMIN
password: '<PASSWORD>'
role: DATADOG_ADMIN
schema: ACCOUNT_USAGE
database: SNOWFLAKE
min_collection_interval: 3600
Recopilación de datos para múltiples entornos
Si deseas recopilar datos para varios entornos de Snowflake, añade cada entorno como una instancia en tu archivo snowflake.d/conf.yaml. Por ejemplo, si necesitas recopilar datos para dos usuarios llamados DATADOG_SYSADMIN y DATADOG_USER:
instances:
- account: example-inc
username: DATADOG_SYSADMIN
password: '<PASSWORD>'
role: SYSADMIN
database: EXAMPLE-INC
- account: example-inc
username: DATADOG_USER
password: '<PASSWORD>'
role: DATADOG_USER
database: EXAMPLE-INC
Configuración de proxy
Snowflake recomienda configurar variables de entorno para la configuración de proxy.
También puedes configurar proxy_host, proxy_port, proxy_user y proxy_password bajo init_config en snowflake.d/conf.yaml.
NOTA: Snowflake formatea automáticamente las configuraciones de proxy y establece variables de entorno de proxy estándar.
Estas variables también afectan todas las solicitudes de integraciones, incluidos los orquestadores como Docker, ECS y Kubernetes.
Conectividad privada a la configuración de Snowflake
Si la conectividad privada (como AWS PrivateLink) está habilitada en Snowflake, puedes configurar la integración de Snowflake actualizando la opción de configuración account con el siguiente formato:
- account: <ACCOUNT>.<REGION_ID>.privatelink
Consultas personalizadas de Snowflake
La integración de Snowflake admite consultas personalizadas. De forma predeterminada, la integración se conecta a la base de datos compartida SNOWFLAKE y al esquema ACCOUNT_USAGE.
Para ejecutar consultas personalizadas en un esquema o una base de datos diferentes, añade otra instancia al ejemplo snowflake.d/conf.yaml y especifica las opciones database y schema.
Asegúrate de que el usuario y el rol tengan acceso a la base de datos o al esquema especificados.
Opciones de configuración
La opción custom_queries tiene las siguientes opciones:
| Opción | Obligatorio | Descripción |
|---|
| query | Sí | Este es el SQL que se va a ejecutar. Puede ser una sentencia simple o un script de varias líneas. Se evalúan todas las filas de los resultados. Utiliza la barra vertical si requieres un script de varias líneas. |
| columns | Sí | Esta es una lista que representa cada columna ordenada de forma secuencial de izquierda a derecha.
Hay 2 datos necesarios:
- name: este es el sufijo que hay que anexar a metric_prefix para formar el nombre completo de la métrica. Si type se especifica como tag, la columna se aplica como etiqueta a las métricas que recoge esta consulta.
- type: este es el método de envío (gauge, count, rate, etc.). También puede configurarse como tag para etiquetar las métricas de la fila con el nombre y el valor (<name>:<row_value>) del elemento en esta columna. |
| tags | No | Una lista de etiquetas (tags) estáticas que pueden aplicarse a las métricas. |
Notas
- Al menos uno de los elementos definidos en
columns debería ser un tipo de métrica (gauge, count, rate, etc.). - El número de elementos en las columnas debe ser igual a la cantidad de columnas devueltas en la consulta.
- El orden en que se definen los elementos en
columns debe ser el mismo orden en que se devuelven en la consulta
custom_queries:
- query: select F3, F2, F1 from Table;
columns:
- name: f3_metric_alias
type: gauge
- name: f2_tagkey
type: tag
- name: f1_metric_alias
type: count
tags:
- test:snowflake
Ejemplo
El siguiente ejemplo es una consulta que cuenta todas las consultas de la [vista QUERY_HISTORY][22] etiquetadas por nombres de base de datos, esquema y almacén.
select count(*), DATABASE_NAME, SCHEMA_NAME, WAREHOUSE_NAME from QUERY_HISTORY group by 2, 3, 4;
Configuración
La configuración de una consulta personalizada en instances tiene el siguiente aspecto:
custom_queries:
- query: select count(*), DATABASE_NAME, SCHEMA_NAME, WAREHOUSE_NAME from QUERY_HISTORY group by 2, 3, 4;
columns:
- name: query.total
type: gauge
- name: database_name
type: tag
- name: schema_name
type: tag
- name: warehouse_name
type: tag
tags:
- test:snowflake
Validación
Para verificar el resultado, busca las métricas utilizando el Resumen de métricas:
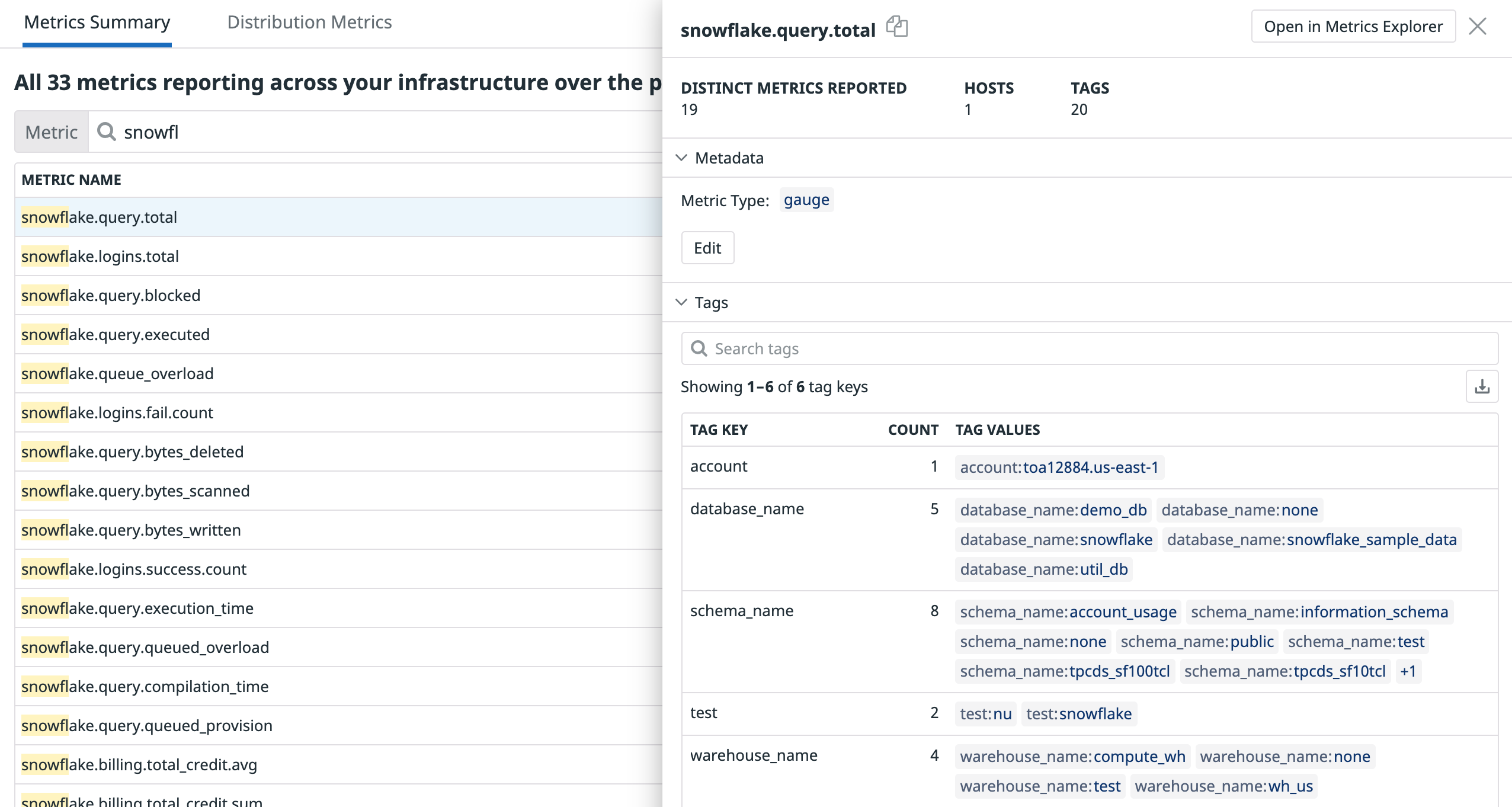
Validación
Ejecuta el subcomando de estado del Agent y busca snowflake en la sección Checks.
Datos recopilados
Nota: Por defecto, solo están habilitadas las métricas de los siguientes grupos de métricas:
snowflake.query.*,
snowflake.billing.*,
snowflake.storage.* y
snowflake.logins.*.
Si deseas recopilar métricas de otros grupos de métricas, consulta el archivo de configuración de ejemplo para esta integración.
Métricas
Eventos
Snowflake no incluye ningún evento.
Checks de servicio
Solucionar problemas
¿Necesitas ayuda? Ponte en contacto con el soporte de Datadog.
Lectura adicional
Más enlaces, artículos y documentación útiles: