Supported OS
Versión de la integración 4.1.0
Habilita la integración de Ceph con Datadog para:
Rastrear el uso del disco en los grupos de almacenamiento Recibir checks de servicio en caso de problemas Monitorizar las métricas de rendimiento de E/S Configuración Instalación El check de Ceph está incluido en el paquete del Datadog Agent , por lo que no necesitas instalar nada más en tus servidores Ceph.
Configuración Edita el archivo ceph.d/conf.yaml, que se encuentra en la carpeta conf.d/ en la raíz del directorio de configuración del Agent .
Para ver todas las opciones de configuración disponibles, consulta el ceph.d/conf.yaml de ejemplo :
init_config :
instances :
- ceph_cmd : /path/to/your/ceph # default is /usr/bin/ceph
use_sudo : true # only if the ceph binary needs sudo on your nodes
Si has habilitado use_sudo, añade una línea como la siguiente a tu archivo sudoers:
dd-agent ALL=(ALL) NOPASSWD:/path/to/your/ceph
Recopilación de logs Disponible para la versión 6.0 o posteriores del Agent
La recopilación de logs está deshabilitada por defecto en el Datadog Agent; habilítala en tu archivo datadog.yaml:
Luego, edita ceph.d/conf.yaml al quitar los comentarios de las líneas logs de la parte inferior. Actualiza la path de los logs con la ruta correcta a tus archivos de logs de Ceph.
logs :
- type : file
path : /var/log/ceph/*.log
source : ceph
service : "<APPLICATION_NAME>"
Reinicia el Agent .
Validación Ejecuta el subcomando de estado del Agent y busca ceph en la sección Checks.
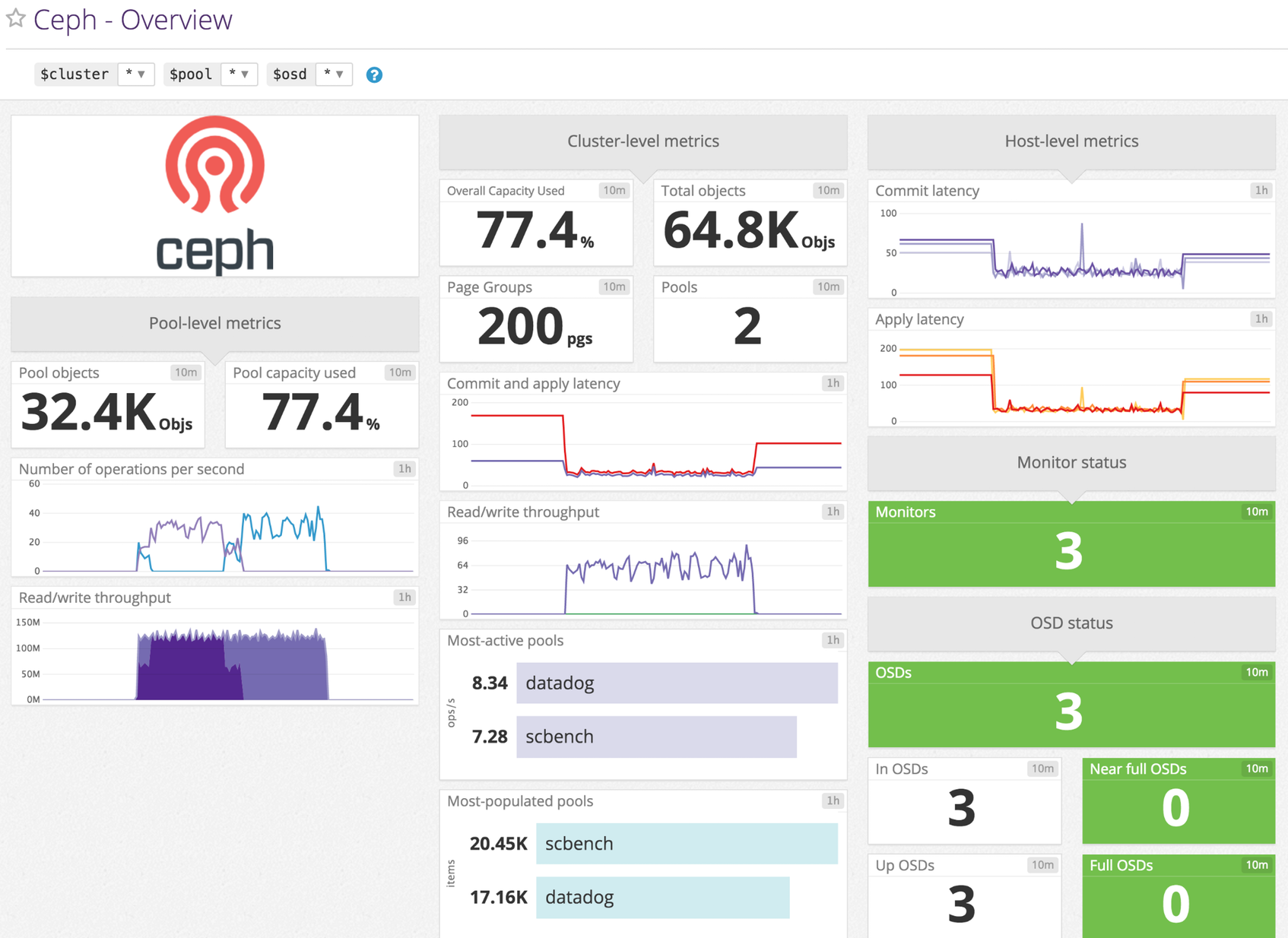
Datos recopilados Métricas ceph.aggregate_pct_used Overall capacity usage metricShown as percent ceph.apply_latency_ms Time taken to flush an update to disksShown as millisecond ceph.class_pct_used Per-class percentage of raw storage usedShown as percent ceph.commit_latency_ms Time taken to commit an operation to the journalShown as millisecond ceph.misplaced_objects Number of objects misplacedShown as item ceph.misplaced_total Total number of objects if there are misplaced objectsShown as item ceph.num_full_osds Number of full osdsShown as item ceph.num_in_osds Number of participating storage daemonsShown as item ceph.num_mons Number of monitor daemonsShown as item ceph.num_near_full_osds Number of nearly full osdsShown as item ceph.num_objects Object count for a given poolShown as item ceph.num_osds Number of known storage daemonsShown as item ceph.num_pgs Number of placement groups availableShown as item ceph.num_pools Number of poolsShown as item ceph.num_up_osds Number of online storage daemonsShown as item ceph.op_per_sec IO operations per second for given poolShown as operation ceph.osd.pct_used Percentage used of full/near full osdsShown as percent ceph.pgstate.active_clean Number of active+clean placement groupsShown as item ceph.read_bytes Per-pool read bytesShown as byte ceph.read_bytes_sec Bytes/second being readShown as byte ceph.read_op_per_sec Per-pool read operations/secondShown as operation ceph.recovery_bytes_per_sec Rate of recovered bytesShown as byte ceph.recovery_keys_per_sec Rate of recovered keysShown as item ceph.recovery_objects_per_sec Rate of recovered objectsShown as item ceph.total_objects Object count from the underlying object store. [v<=3 only]Shown as item ceph.write_bytes Per-pool write bytesShown as byte ceph.write_bytes_sec Bytes/second being writtenShown as byte ceph.write_op_per_sec Per-pool write operations/secondShown as operation
Note : If you are running Ceph luminous or later, the ceph.osd.pct_used metric is not included.
Nota : Si estás ejecutando Ceph Luminous o posterior, la métrica ceph.osd.pct_used no está incluida.
Eventos El check de Ceph no incluye eventos.
Checks de servicio ceph.overall_status
Returns OK if your ceph cluster status is HEALTH_OK, WARNING if it’s HEALTH_WARNING, CRITICAL otherwise.
Statuses: ok, warning, critical
ceph.osd_down
Returns OK if you have no down OSD. Otherwise, returns WARNING if the severity is HEALTH_WARN, else CRITICAL.
Statuses: ok, warning, critical
ceph.osd_orphan
Returns OK if you have no orphan OSD. Otherwise, returns WARNING if the severity is HEALTH_WARN, else CRITICAL.
Statuses: ok, warning, critical
ceph.osd_full
Returns OK if your OSDs are not full. Otherwise, returns WARNING if the severity is HEALTH_WARN, else CRITICAL.
Statuses: ok, warning, critical
ceph.osd_nearfull
Returns OK if your OSDs are not near full. Otherwise, returns WARNING if the severity is HEALTH_WARN, else CRITICAL.
Statuses: ok, warning, critical
ceph.pool_full
Returns OK if your pools have not reached their quota. Otherwise, returns WARNING if the severity is HEALTH_WARN, else CRITICAL.
Statuses: ok, warning, critical
ceph.pool_near_full
Returns OK if your pools are not near reaching their quota. Otherwise, returns WARNING if the severity is HEALTH_WARN, else CRITICAL.
Statuses: ok, warning, critical
ceph.pg_availability
Returns OK if there is full data availability. Otherwise, returns WARNING if the severity is HEALTH_WARN, else CRITICAL.
Statuses: ok, warning, critical
ceph.pg_degraded
Returns OK if there is full data redundancy. Otherwise, returns WARNING if the severity is HEALTH_WARN, else CRITICAL.
Statuses: ok, warning, critical
ceph.pg_degraded_full
Returns OK if there is enough space in the cluster for data redundancy. Otherwise, returns WARNING if the severity is HEALTH_WARN, else CRITICAL.
Statuses: ok, warning, critical
ceph.pg_damaged
Returns OK if there are no inconsistencies after data scrubing. Otherwise, returns WARNING if the severity is HEALTH_WARN, else CRITICAL.
Statuses: ok, warning, critical
ceph.pg_not_scrubbed
Returns OK if the PGs were scrubbed recently. Otherwise, returns WARNING if the severity is HEALTH_WARN, else CRITICAL.
Statuses: ok, warning, critical
ceph.pg_not_deep_scrubbed
Returns OK if the PGs were deep scrubbed recently. Otherwise, returns WARNING if the severity is HEALTH_WARN, else CRITICAL.
Statuses: ok, warning, critical
ceph.cache_pool_near_full
Returns OK if the cache pools are not near full. Otherwise, returns WARNING if the severity is HEALTH_WARN, else CRITICAL.
Statuses: ok, warning, critical
ceph.too_few_pgs
Returns OK if the number of PGs is above the min threshold. Otherwise, returns WARNING if the severity is HEALTH_WARN, else CRITICAL.
Statuses: ok, warning, critical
ceph.too_many_pgs
Returns OK if the number of PGs is below the max threshold. Otherwise, returns WARNING if the severity is HEALTH_WARN, else CRITICAL.
Statuses: ok, warning, critical
ceph.object_unfound
Returns OK if all objects can be found. Otherwise, returns WARNING if the severity is HEALTH_WARN, else CRITICAL.
Statuses: ok, warning, critical
ceph.request_slow
Returns OK requests are taking a normal time to process. Otherwise, returns WARNING if the severity is HEALTH_WARN, else CRITICAL.
Statuses: ok, warning, critical
ceph.request_stuck
Returns OK requests are taking a normal time to process. Otherwise, returns WARNING if the severity is HEALTH_WARN, else CRITICAL.
Statuses: ok, warning, critical
Solucionar problemas ¿Necesitas ayuda? Consulta el servicio de asistencia de Datadog .
Referencias adicionales