Data Jobs Monitoring helps you observe, troubleshoot, and cost-optimize your Databricks jobs and clusters.
This page is limited to documentation for ingesting Databricks cluster utilization metrics and logs.
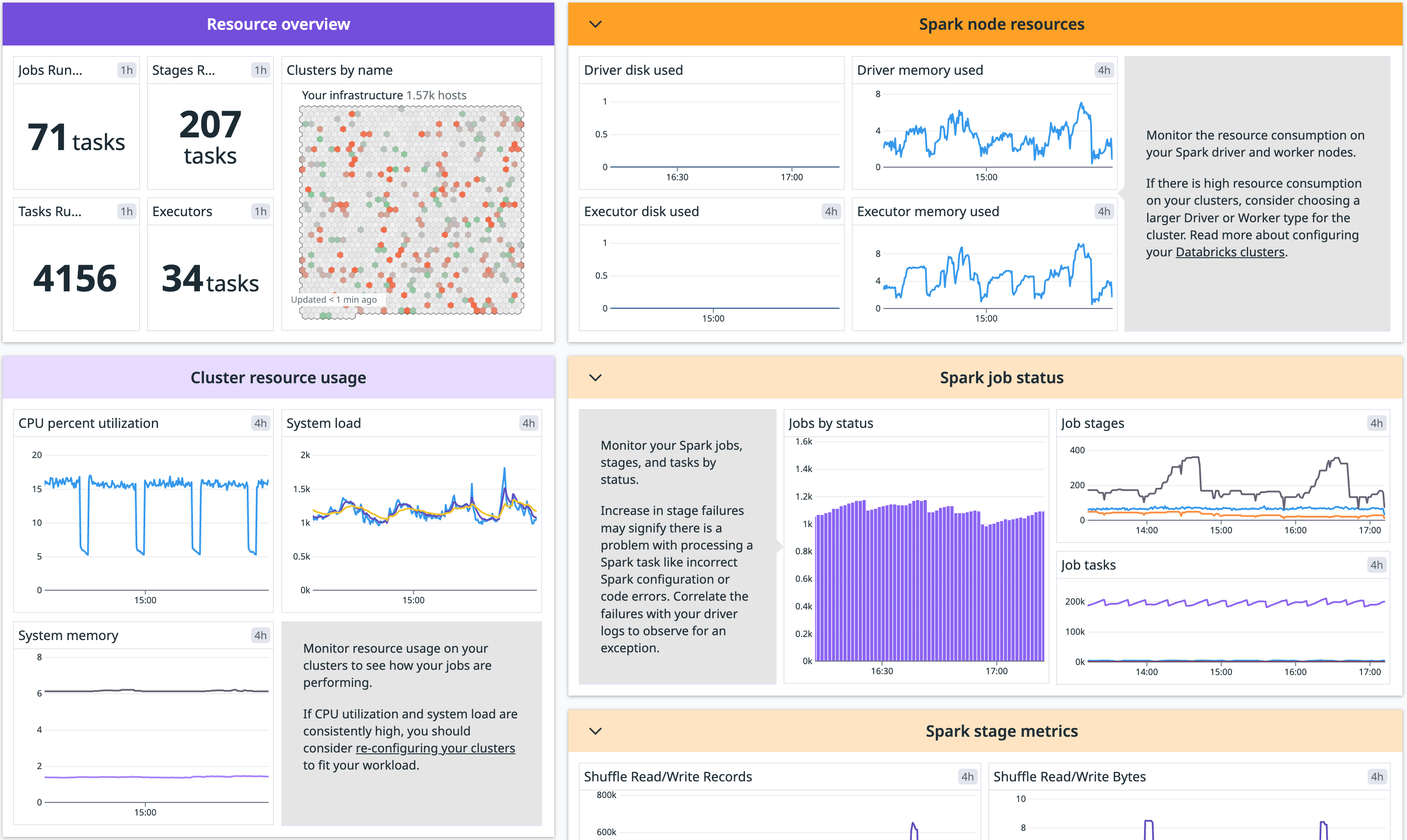
Overview
Monitor your Databricks clusters with the Datadog Spark integration.
This integration unifies logs, infrastructure metrics, and Spark performance metrics, providing real-time visibility into the health of your nodes and the performance of your jobs. It can help you debug errors, fine-tune performance, and identify issues such as inefficient data partitioning or clusters running out of memory.
For feature details, see Monitor Databricks with Datadog.
Setup
Installation
Monitor Databricks Spark applications with the Datadog Spark integration. Install the Datadog Agent on your clusters following the configuration instructions for your appropriate cluster. After that, install the Spark integration on Datadog to autoinstall the Databricks Overview dashboard.
Configuration
Configure the Spark integration to monitor your Apache Spark Cluster on Databricks and collect system and Spark metrics.
Each script described below can be modified to suits your needs. For instance, you can:
- Add specific tags to your instances.
- Modify the Spark integration configuration.
You can also define or modify environment variables with the cluster-scoped init script path using the UI, Databricks CLI, or invoking the Clusters API:
- Set
DD_API_KEY to better identify your clusters. - Set
DD_ENV to better identify your clusters. - Set
DD_SITE to your site: datadoghq.com
For security reasons, it's not recommended to define the `DD_API_KEY` environment variable in plain text directly in the UI. Instead, use
Databricks secrets.
With a global init script
A global init script runs on every cluster created in your workspace. Global init scripts are useful when you want to enforce organization-wide library configurations or security screens.
Only workspace admins can manage global init scripts.
Global init scripts only run on clusters configured with single user or legacy no-isolation shared access mode. Therefore, Databricks recommends configuring all init scripts as cluster-scoped and managing them across your workspace using cluster policies.
Use the Databricks UI to edit the global init scripts:
- Choose one of the following scripts to install the Agent on the driver or on the driver and worker nodes of the cluster.
- Modify the script to suit your needs. For example, you can add tags or define a specific configuration for the integration.
- Go to the Admin Settings and click the Global Init Scripts tab.
- Click on the + Add button.
- Name the script, for example
Datadog init script and then paste it in the Script field. - Click on the Enabled toggle to enable it.
- Click on the Add button.
After these steps, any new cluster uses the script automatically. More information on global init scripts can be found in the Databricks official documentation.
You can define several init scripts and specify their order in the UI.
Install the Datadog Agent on driver
Install the Datadog Agent on the driver node of the cluster.
You need to define the value of the `DD_API_KEY` variable inside the script.
#!/bin/bash
cat <<EOF > /tmp/start_datadog.sh
#!/bin/bash
date -u +"%Y-%m-%d %H:%M:%S UTC"
echo "Running on the driver? \$DB_IS_DRIVER"
echo "Driver ip: \$DB_DRIVER_IP"
DB_CLUSTER_NAME=$(echo "$DB_CLUSTER_NAME" | sed -e 's/ /_/g' -e "s/'/_/g")
DD_API_KEY='<YOUR_API_KEY>'
if [[ \${DB_IS_DRIVER} = "TRUE" ]]; then
echo "Installing Datadog Agent on the driver..."
# CONFIGURE HOST TAGS FOR DRIVER
DD_TAGS="environment:\${DD_ENV}","databricks_cluster_id:\${DB_CLUSTER_ID}","databricks_cluster_name:\${DB_CLUSTER_NAME}","spark_host_ip:\${DB_DRIVER_IP}","spark_node:driver","databricks_instance_type:\${DB_INSTANCE_TYPE}","databricks_is_job_cluster:\${DB_IS_JOB_CLUSTER}"
# INSTALL THE LATEST DATADOG AGENT 7 ON DRIVER AND WORKER NODES
DD_INSTALL_ONLY=true \
DD_API_KEY=\$DD_API_KEY \
DD_HOST_TAGS=\$DD_TAGS \
DD_HOSTNAME="\$(hostname | xargs)" \
DD_SITE="\${DD_SITE:-datadoghq.com}" \
bash -c "\$(curl -L https://s3.amazonaws.com/dd-agent/scripts/install_script_agent7.sh)"
# Avoid conflicts on port 6062
echo "process_config.expvar_port: 6063" >> /etc/datadog-agent/datadog.yaml
echo "Datadog Agent is installed"
while [ -z \$DB_DRIVER_PORT ]; do
if [ -e "/tmp/driver-env.sh" ]; then
DB_DRIVER_PORT="\$(grep -i "CONF_UI_PORT" /tmp/driver-env.sh | cut -d'=' -f2)"
fi
echo "Waiting 2 seconds for DB_DRIVER_PORT"
sleep 2
done
echo "DB_DRIVER_PORT=\$DB_DRIVER_PORT"
# WRITING CONFIG FILE FOR SPARK INTEGRATION WITH STRUCTURED STREAMING METRICS ENABLED
# MODIFY TO INCLUDE OTHER OPTIONS IN spark.d/conf.yaml.example
echo "init_config:
instances:
- spark_url: http://\${DB_DRIVER_IP}:\${DB_DRIVER_PORT}
spark_cluster_mode: spark_driver_mode
cluster_name: \${DB_CLUSTER_NAME}
streaming_metrics: true
executor_level_metrics: true
logs:
- type: file
path: /databricks/driver/logs/*.log
source: spark
service: databricks
log_processing_rules:
- type: multi_line
name: new_log_start_with_date
pattern: \d{2,4}[\-\/]\d{2,4}[\-\/]\d{2,4}.*" > /etc/datadog-agent/conf.d/spark.d/spark.yaml
echo "Spark integration configured"
# ENABLE LOGS IN datadog.yaml TO COLLECT DRIVER LOGS
sed -i '/.*logs_enabled:.*/a logs_enabled: true' /etc/datadog-agent/datadog.yaml
fi
echo "Restart the agent"
sudo service datadog-agent restart
EOF
chmod a+x /tmp/start_datadog.sh
/tmp/start_datadog.sh >> /tmp/datadog_start.log 2>&1 & disown
Install the Datadog Agent on driver and worker nodes
Install the Datadog Agent on the driver and worker nodes of the cluster.
You will need to define the value of the `DD_API_KEY` variable inside the script.
#!/bin/bash
cat <<EOF > /tmp/start_datadog.sh
#!/bin/bash
date -u +"%Y-%m-%d %H:%M:%S UTC"
echo "Running on the driver? \$DB_IS_DRIVER"
echo "Driver ip: \$DB_DRIVER_IP"
DB_CLUSTER_NAME=$(echo "$DB_CLUSTER_NAME" | sed -e 's/ /_/g' -e "s/'/_/g")
DD_API_KEY='<YOUR_API_KEY>'
if [[ \${DB_IS_DRIVER} = "TRUE" ]]; then
echo "Installing Datadog Agent on the driver (master node)."
# CONFIGURE HOST TAGS FOR DRIVER
DD_TAGS="environment:\${DD_ENV}","databricks_cluster_id:\${DB_CLUSTER_ID}","databricks_cluster_name:\${DB_CLUSTER_NAME}","spark_host_ip:\${DB_DRIVER_IP}","spark_node:driver","databricks_instance_type:\${DB_INSTANCE_TYPE}","databricks_is_job_cluster:\${DB_IS_JOB_CLUSTER}"
# INSTALL THE LATEST DATADOG AGENT 7 ON DRIVER AND WORKER NODES
DD_INSTALL_ONLY=true \
DD_API_KEY=\$DD_API_KEY \
DD_HOST_TAGS=\$DD_TAGS \
DD_HOSTNAME="\$(hostname | xargs)" \
DD_SITE="\${DD_SITE:-datadoghq.com}" \
bash -c "\$(curl -L https://s3.amazonaws.com/dd-agent/scripts/install_script_agent7.sh)"
echo "Datadog Agent is installed"
while [ -z \$DB_DRIVER_PORT ]; do
if [ -e "/tmp/driver-env.sh" ]; then
DB_DRIVER_PORT="\$(grep -i "CONF_UI_PORT" /tmp/driver-env.sh | cut -d'=' -f2)"
fi
echo "Waiting 2 seconds for DB_DRIVER_PORT"
sleep 2
done
echo "DB_DRIVER_PORT=\$DB_DRIVER_PORT"
# WRITING CONFIG FILE FOR SPARK INTEGRATION WITH STRUCTURED STREAMING METRICS ENABLED
# MODIFY TO INCLUDE OTHER OPTIONS IN spark.d/conf.yaml.example
echo "init_config:
instances:
- spark_url: http://\${DB_DRIVER_IP}:\${DB_DRIVER_PORT}
spark_cluster_mode: spark_driver_mode
cluster_name: \${DB_CLUSTER_NAME}
streaming_metrics: true
executor_level_metrics: true
logs:
- type: file
path: /databricks/driver/logs/*.log
source: spark
service: databricks
log_processing_rules:
- type: multi_line
name: new_log_start_with_date
pattern: \d{2,4}[\-\/]\d{2,4}[\-\/]\d{2,4}.*" > /etc/datadog-agent/conf.d/spark.d/spark.yaml
echo "Spark integration configured"
# ENABLE LOGS IN datadog.yaml TO COLLECT DRIVER LOGS
sed -i '/.*logs_enabled:.*/a logs_enabled: true' /etc/datadog-agent/datadog.yaml
else
echo "Installing Datadog Agent on the worker."
# CONFIGURE HOST TAGS FOR WORKERS
DD_TAGS="environment:\${DD_ENV}","databricks_cluster_id:\${DB_CLUSTER_ID}","databricks_cluster_name:\${DB_CLUSTER_NAME}","spark_host_ip:\${SPARK_LOCAL_IP}","spark_node:worker","databricks_instance_type:\${DB_INSTANCE_TYPE}","databricks_is_job_cluster:\${DB_IS_JOB_CLUSTER}"
# INSTALL THE LATEST DATADOG AGENT 7 ON DRIVER AND WORKER NODES
# CONFIGURE HOSTNAME EXPLICITLY IN datadog.yaml TO PREVENT AGENT FROM FAILING ON VERSION 7.40+
# SEE https://github.com/DataDog/datadog-agent/issues/14152 FOR CHANGE
DD_INSTALL_ONLY=true DD_API_KEY=\$DD_API_KEY DD_HOST_TAGS=\$DD_TAGS DD_HOSTNAME="\$(hostname | xargs)" bash -c "\$(curl -L https://s3.amazonaws.com/dd-agent/scripts/install_script_agent7.sh)"
echo "Datadog Agent is installed"
fi
# Avoid conflicts on port 6062
echo "process_config.expvar_port: 6063" >> /etc/datadog-agent/datadog.yaml
echo "Restart the agent"
sudo service datadog-agent restart
EOF
chmod a+x /tmp/start_datadog.sh
/tmp/start_datadog.sh >> /tmp/datadog_start.log 2>&1 & disown
With a cluster-scoped init script
Cluster-scoped init scripts are init scripts defined in a cluster configuration. Cluster-scoped init scripts apply to both clusters you create and those created to run jobs. Databricks supports configuration and storage of init scripts through:
- Workspace Files
- Unity Catalog Volumes
- Cloud Object Storage
Use the Databricks UI to edit the cluster to run the init script:
- Choose one of the following scripts to install the Agent on the driver or on the driver and worker nodes of the cluster.
- Modify the script to suit your needs. For example, you can add tags or define a specific configuration for the integration.
- Save the script into your workspace with the Workspace menu on the left. If using Unity Catalog Volume, save the script in your Volume with the Catalog menu on the left.
- On the cluster configuration page, click the Advanced options toggle.
- In the Environment variables, specify the
DD_API_KEY environment variable and, optionally, the DD_ENV and the DD_SITE environment variables. - Go to the Init Scripts tab.
- In the Destination dropdown, select the
Workspace destination type. If using Unity Catalog Volume, in the Destination dropdown, select the Volume destination type. - Specify a path to the init script.
- Click on the Add button.
If you stored your datadog_init_script.sh directly in the Shared workspace, you can access the file at the following path: /Shared/datadog_init_script.sh.
If you stored your datadog_init_script.sh directly in a user workspace, you can access the file at the following path: /Users/$EMAIL_ADDRESS/datadog_init_script.sh.
If you stored your datadog_init_script.sh directly in a Unity Catalog Volume, you can access the file at the following path: /Volumes/$VOLUME_PATH/datadog_init_script.sh.
More information on cluster init scripts can be found in the Databricks official documentation.
Install the Datadog Agent on Driver
Install the Datadog Agent on the driver node of the cluster.
#!/bin/bash
cat <<EOF > /tmp/start_datadog.sh
#!/bin/bash
date -u +"%Y-%m-%d %H:%M:%S UTC"
echo "Running on the driver? \$DB_IS_DRIVER"
echo "Driver ip: \$DB_DRIVER_IP"
DB_CLUSTER_NAME=$(echo "$DB_CLUSTER_NAME" | sed -e 's/ /_/g' -e "s/'/_/g")
if [[ \${DB_IS_DRIVER} = "TRUE" ]]; then
echo "Installing Datadog Agent on the driver..."
# CONFIGURE HOST TAGS FOR DRIVER
DD_TAGS="environment:\${DD_ENV}","databricks_cluster_id:\${DB_CLUSTER_ID}","databricks_cluster_name:\${DB_CLUSTER_NAME}","spark_host_ip:\${DB_DRIVER_IP}","spark_node:driver","databricks_instance_type:\${DB_INSTANCE_TYPE}","databricks_is_job_cluster:\${DB_IS_JOB_CLUSTER}"
# INSTALL THE LATEST DATADOG AGENT 7 ON DRIVER AND WORKER NODES
DD_INSTALL_ONLY=true \
DD_API_KEY=\$DD_API_KEY \
DD_HOST_TAGS=\$DD_TAGS \
DD_HOSTNAME="\$(hostname | xargs)" \
DD_SITE="\${DD_SITE:-datadoghq.com}" \
bash -c "\$(curl -L https://s3.amazonaws.com/dd-agent/scripts/install_script_agent7.sh)"
# Avoid conflicts on port 6062
echo "process_config.expvar_port: 6063" >> /etc/datadog-agent/datadog.yaml
echo "Datadog Agent is installed"
while [ -z \$DB_DRIVER_PORT ]; do
if [ -e "/tmp/driver-env.sh" ]; then
DB_DRIVER_PORT="\$(grep -i "CONF_UI_PORT" /tmp/driver-env.sh | cut -d'=' -f2)"
fi
echo "Waiting 2 seconds for DB_DRIVER_PORT"
sleep 2
done
echo "DB_DRIVER_PORT=\$DB_DRIVER_PORT"
# WRITING CONFIG FILE FOR SPARK INTEGRATION WITH STRUCTURED STREAMING METRICS ENABLED
# MODIFY TO INCLUDE OTHER OPTIONS IN spark.d/conf.yaml.example
echo "init_config:
instances:
- spark_url: http://\${DB_DRIVER_IP}:\${DB_DRIVER_PORT}
spark_cluster_mode: spark_driver_mode
cluster_name: \${DB_CLUSTER_NAME}
streaming_metrics: true
executor_level_metrics: true
logs:
- type: file
path: /databricks/driver/logs/*.log
source: spark
service: databricks
log_processing_rules:
- type: multi_line
name: new_log_start_with_date
pattern: \d{2,4}[\-\/]\d{2,4}[\-\/]\d{2,4}.*" > /etc/datadog-agent/conf.d/spark.d/spark.yaml
echo "Spark integration configured"
# ENABLE LOGS IN datadog.yaml TO COLLECT DRIVER LOGS
sed -i '/.*logs_enabled:.*/a logs_enabled: true' /etc/datadog-agent/datadog.yaml
fi
echo "Restart the agent"
sudo service datadog-agent restart
EOF
chmod a+x /tmp/start_datadog.sh
/tmp/start_datadog.sh >> /tmp/datadog_start.log 2>&1 & disown
Install the Datadog Agent on driver and worker nodes
Install the Datadog Agent on the driver and worker nodes of the cluster.
#!/bin/bash
cat <<EOF > /tmp/start_datadog.sh
#!/bin/bash
date -u +"%Y-%m-%d %H:%M:%S UTC"
echo "Running on the driver? \$DB_IS_DRIVER"
echo "Driver ip: \$DB_DRIVER_IP"
DB_CLUSTER_NAME=$(echo "$DB_CLUSTER_NAME" | sed -e 's/ /_/g' -e "s/'/_/g")
if [[ \${DB_IS_DRIVER} = "TRUE" ]]; then
echo "Installing Datadog Agent on the driver (master node)."
# CONFIGURE HOST TAGS FOR DRIVER
DD_TAGS="environment:\${DD_ENV}","databricks_cluster_id:\${DB_CLUSTER_ID}","databricks_cluster_name:\${DB_CLUSTER_NAME}","spark_host_ip:\${DB_DRIVER_IP}","spark_node:driver","databricks_instance_type:\${DB_INSTANCE_TYPE}","databricks_is_job_cluster:\${DB_IS_JOB_CLUSTER}"
# INSTALL THE LATEST DATADOG AGENT 7 ON DRIVER AND WORKER NODES
DD_INSTALL_ONLY=true \
DD_API_KEY=\$DD_API_KEY \
DD_HOST_TAGS=\$DD_TAGS \
DD_HOSTNAME="\$(hostname | xargs)" \
DD_SITE="\${DD_SITE:-datadoghq.com}" \
bash -c "\$(curl -L https://s3.amazonaws.com/dd-agent/scripts/install_script_agent7.sh)"
echo "Datadog Agent is installed"
while [ -z \$DB_DRIVER_PORT ]; do
if [ -e "/tmp/driver-env.sh" ]; then
DB_DRIVER_PORT="\$(grep -i "CONF_UI_PORT" /tmp/driver-env.sh | cut -d'=' -f2)"
fi
echo "Waiting 2 seconds for DB_DRIVER_PORT"
sleep 2
done
echo "DB_DRIVER_PORT=\$DB_DRIVER_PORT"
# WRITING CONFIG FILE FOR SPARK INTEGRATION WITH STRUCTURED STREAMING METRICS ENABLED
# MODIFY TO INCLUDE OTHER OPTIONS IN spark.d/conf.yaml.example
echo "init_config:
instances:
- spark_url: http://\${DB_DRIVER_IP}:\${DB_DRIVER_PORT}
spark_cluster_mode: spark_driver_mode
cluster_name: \${DB_CLUSTER_NAME}
streaming_metrics: true
executor_level_metrics: true
logs:
- type: file
path: /databricks/driver/logs/*.log
source: spark
service: databricks
log_processing_rules:
- type: multi_line
name: new_log_start_with_date
pattern: \d{2,4}[\-\/]\d{2,4}[\-\/]\d{2,4}.*" > /etc/datadog-agent/conf.d/spark.d/spark.yaml
echo "Spark integration configured"
# ENABLE LOGS IN datadog.yaml TO COLLECT DRIVER LOGS
sed -i '/.*logs_enabled:.*/a logs_enabled: true' /etc/datadog-agent/datadog.yaml
else
echo "Installing Datadog Agent on the worker."
# CONFIGURE HOST TAGS FOR WORKERS
DD_TAGS="environment:\${DD_ENV}","databricks_cluster_id:\${DB_CLUSTER_ID}","databricks_cluster_name:\${DB_CLUSTER_NAME}","spark_host_ip:\${SPARK_LOCAL_IP}","spark_node:worker","databricks_instance_type:\${DB_INSTANCE_TYPE}","databricks_is_job_cluster:\${DB_IS_JOB_CLUSTER}"
# INSTALL THE LATEST DATADOG AGENT 7 ON DRIVER AND WORKER NODES
# CONFIGURE HOSTNAME EXPLICITLY IN datadog.yaml TO PREVENT AGENT FROM FAILING ON VERSION 7.40+
# SEE https://github.com/DataDog/datadog-agent/issues/14152 FOR CHANGE
DD_INSTALL_ONLY=true DD_API_KEY=\$DD_API_KEY DD_HOST_TAGS=\$DD_TAGS DD_HOSTNAME="\$(hostname | xargs)" bash -c "\$(curl -L https://s3.amazonaws.com/dd-agent/scripts/install_script_agent7.sh)"
echo "Datadog Agent is installed"
fi
# Avoid conflicts on port 6062
echo "process_config.expvar_port: 6063" >> /etc/datadog-agent/datadog.yaml
echo "Restart the agent"
sudo service datadog-agent restart
EOF
chmod a+x /tmp/start_datadog.sh
/tmp/start_datadog.sh >> /tmp/datadog_start.log 2>&1 & disown
Data Collected
Metrics
See the Spark integration documentation for a list of metrics collected.
Service Checks
See the Spark integration documentation for the list of service checks collected.
Events
The Databricks integration does not include any events.
Troubleshooting
You can troubleshoot issues yourself by enabling the Databricks web terminal or by using a Databricks Notebook. Consult the Agent Troubleshooting documentation for information on useful troubleshooting steps.
Need help? Contact Datadog support.
Further Reading
Additional helpful documentation, links, and articles: