- 重要な情報
- はじめに
- Datadog
- Datadog サイト
- DevSecOps
- AWS Lambda のサーバーレス
- エージェント
- インテグレーション
- コンテナ
- ダッシュボード
- アラート設定
- ログ管理
- トレーシング
- プロファイラー
- タグ
- API
- Service Catalog
- Session Replay
- Continuous Testing
- Synthetic モニタリング
- Incident Management
- Database Monitoring
- Cloud Security Management
- Cloud SIEM
- Application Security Management
- Workflow Automation
- CI Visibility
- Test Visibility
- Intelligent Test Runner
- Code Analysis
- Learning Center
- Support
- 用語集
- Standard Attributes
- ガイド
- インテグレーション
- エージェント
- OpenTelemetry
- 開発者
- 認可
- DogStatsD
- カスタムチェック
- インテグレーション
- Create an Agent-based Integration
- Create an API Integration
- Create a Log Pipeline
- Integration Assets Reference
- Build a Marketplace Offering
- Create a Tile
- Create an Integration Dashboard
- Create a Recommended Monitor
- Create a Cloud SIEM Detection Rule
- OAuth for Integrations
- Install Agent Integration Developer Tool
- サービスのチェック
- IDE インテグレーション
- コミュニティ
- ガイド
- API
- モバイルアプリケーション
- CoScreen
- Cloudcraft
- アプリ内
- Service Management
- インフラストラクチャー
- アプリケーションパフォーマンス
- APM
- Continuous Profiler
- データベース モニタリング
- Data Streams Monitoring
- Data Jobs Monitoring
- Digital Experience
- Software Delivery
- CI Visibility (CI/CDの可視化)
- CD Visibility
- Test Visibility
- Intelligent Test Runner
- Code Analysis
- Quality Gates
- DORA Metrics
- セキュリティ
- セキュリティの概要
- Cloud SIEM
- クラウド セキュリティ マネジメント
- Application Security Management
- AI Observability
- ログ管理
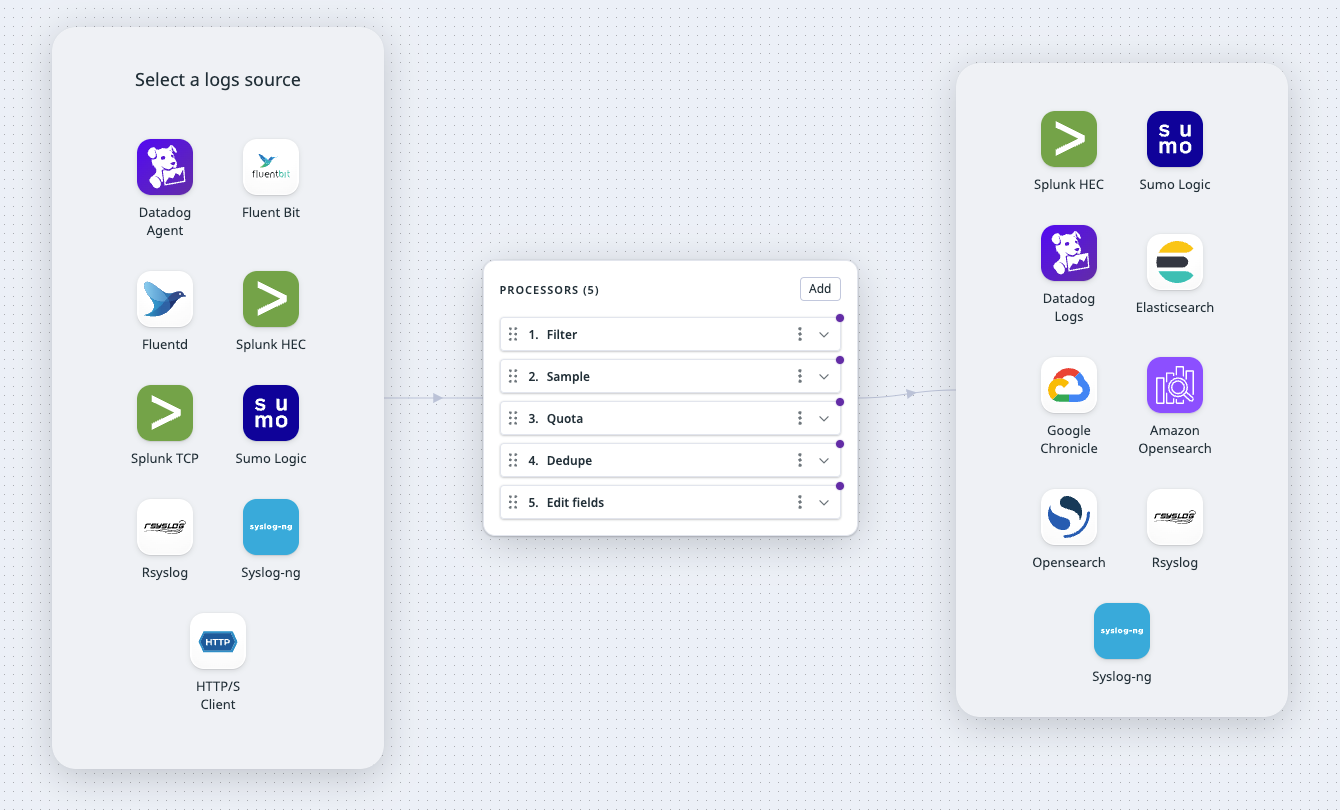
- Observability Pipelines(観測データの制御)
- ログ管理
- 管理