Data Jobs Monitoring te ayuda a observar, solucionar problemas y optimizar los costos de tus trabajos y clústeres de Databricks.
Esta página se limita a la documentación para la ingesta de las métricas y logs de utilización de clústeres de Databricks.
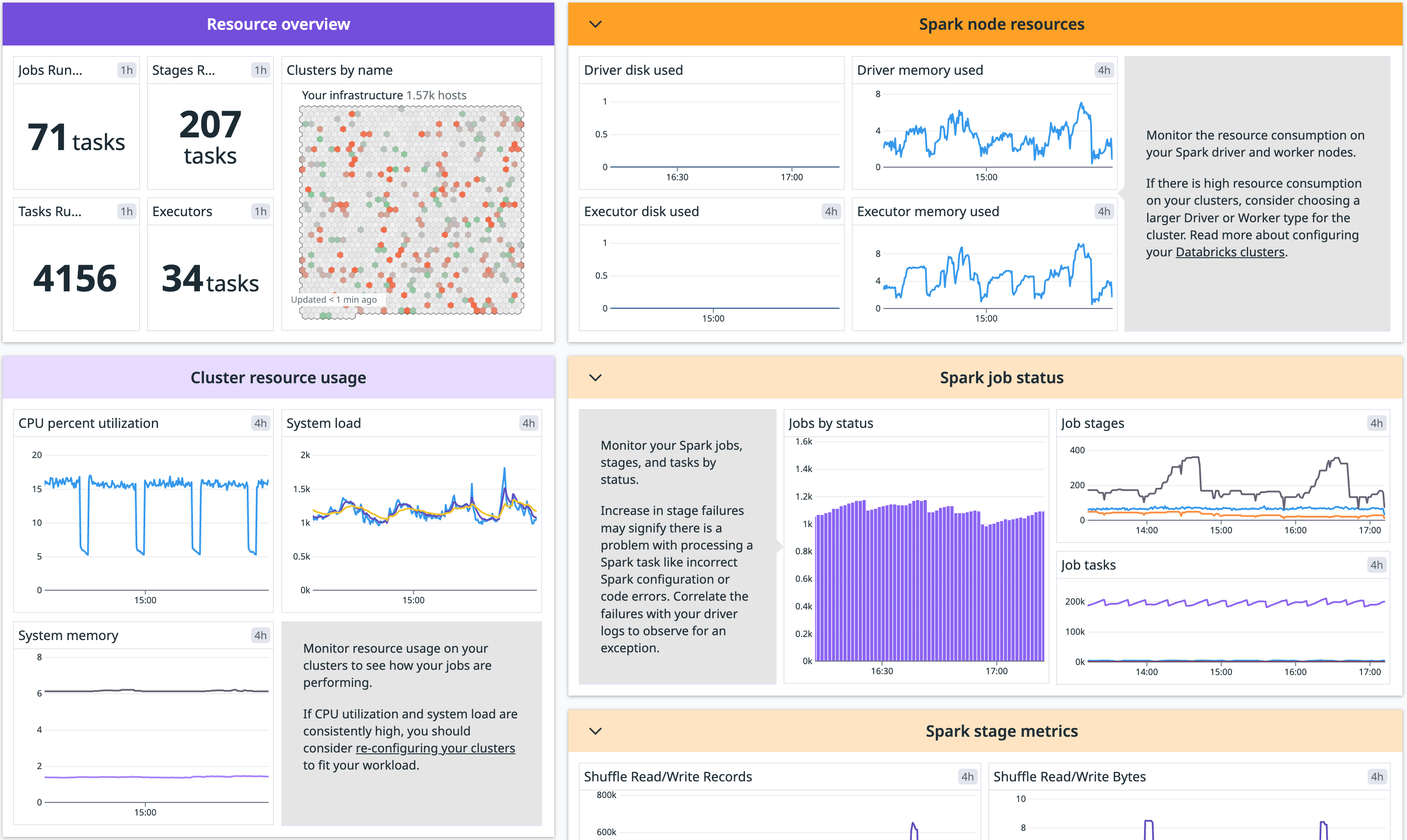
Monitoriza tus clústeres de Databricks con la integración de Spark de Datadog.
Esta integración unifica logs, métricas de la infraestructura y del rendimiento de Spark, proporcionando visibilidad en tiempo real del estado de tus nodos y el rendimiento de tus trabajos. Puede ayudarte a depurar errores, ajustar el rendimiento e identificar problemas como particiones de datos ineficientes o clústeres con la memoria agotada.
Para más detalles, consulta Monitorizar Databricks con Datadog.
Configuración
Instalación
Monitoriza Databricks Spark con la integración de Datadog Spark. Instala el Datadog Agent en tus clústeres siguiendo las instrucciones para la configuración para tu clúster apropiado. Después, instala la integración de Spark en Datadog para autoinstalar el dashboard de Información general de Databricks.
Configuración
Configura la integración de Spark para monitorizar tu clúster de Apache Spark en Databricks y recopilar el sistema y las métricas de Spark.
Cada script descrito a continuación puede modificarse para adaptarlo a tus necesidades. Por ejemplo, puedes:
- Añadir etiquetas (tags) específicas a tus instancias.
- Modificar la configuración de la integración de Spark.
También puedes definir o modificar variables de entorno con la ruta del script de inicio del ámbito del clúster a través de la interfaz de usuario, de la CLI de Databricks o invocando la API de clústeres.
- Configura
DD_API_KEY para identificar mejor tus clústeres. - Configura
DD_ENV para identificar mejor tus clústeres. - Configura
DD_SITE en tu sitio: datadoghq.com
Por razones de seguridad, no se recomienda definir la variable de entorno `DD_API_KEY` en texto simple directamente en la interfaz de usuario. En su lugar, utiliza
secretos de Databricks.
Con un script de inicio global
Un script de inicial global se ejecuta en cada clúster creado en tu espacio de trabajo. Las secuencias de scripts de inicio globales son útiles cuando se desea aplicar configuraciones o pantallas de seguridad de bibliotecas en toda la organización.
Solo los administradores del espacio de trabajo pueden gestionar scripts de inicio globales.
Los scripts de inicio globales solo se ejecutan en clústeres configurados con un único usuario o en el modo de acceso compartido sin aislamiento de legacy. Por lo tanto, Databricks recomienda configurar todos los scripts de inicio como ámbito de clúster y gestionarlos en todo el espacio de trabajo mediante políticas de clúster.
Utiliza la interfaz de usuario de Databricks para editar los scripts de inicio globales:
- Elige uno de los siguientes scripts para instalar el Agent en el controlador o en los nodos controlador y trabajador del clúster.
- Modifica el script para adaptarlo a tus necesidades. Por ejemplo, puedes añadir etiquetas (tags) o definir una configuración específica para la integración.
- Ve a la configuración de administración y haz clic en la pestaña Scripts de inicio globales.
- Haz clic en el botón + Añadir.
- Dale un nombre al script, por ejemplo
Datadog init script y pégalo en el campo Script. - Haz clic en el conmutador Habilitado para activarlo.
- Haz clic en el botón Añadir.
Después de estos pasos, cualquier nuevo clúster utiliza el script en forma automática. Puedes encontrar más información sobre scripts de inicio globales en la documentación oficial de Databricks.
Puedes definir varios scripts de inicio y especificar su orden en la interfaz de usuario.
Instala el Datadog Agent en el controlador
Instala el Datadog Agent en el nodo del controlador del clúster.
Es necesario definir el valor de la variable `DD_API_KEY` en el script.
``script de shell
#!/bin/bash
cat «EOF > /tmp/start_datadog.sh
#!/bin/bash
fecha -u +"%Y-%m-%d %H:%M:%S UTC"
eco “Running on the driver? $DB_IS_DRIVER”
eco “Driver ip: $DB_DRIVER_IP”
DB_CLUSTER_NAME=$(echo “$DB_CLUSTER_NAME” | sed -e ’s/ //g’ -e “s/’//g”)
DD_API_KEY=’<YOUR_API_KEY>'
si [[ ${DB_IS_DRIVER} = “TRUE” ]]; entonces
eco “Installing Datadog Agent on the driver…”
DD_TAGS=“entorno:${DD_ENV}”, “databricks_cluster_id:${DB_CLUSTER_ID}”, “databricks_cluster_name:${DB_CLUSTER_NAME}”, “spark_host_ip:${DB_DRIVER_IP}”, “spark_node:driver”, “databricks_instance_type:${DB_INSTANCE_TYPE}”, “databricks_is_job_cluster:${DB_IS_JOB_CLUSTER}”.
INSTALAR LA ÚLTIMA VERSIÓN DEL DATADOG AGENT 7 EN LOS NODOS CONTROLADOR Y TRABAJADOR
DD_INSTALL_ONLY=true
DD_API_KEY=$DD_API_KEY
DD_HOST_TAGS=$DD_TAGS
DD_HOSTNAME="$(hostname | xargs)"
DD_SITE="${DD_SITE:-datadoghq.com}"
bash -c “$(curl -L https://s3.amazonaws.com/dd-agent/scripts/install_script_agent7.sh)"
Evitar conflictos en el puerto 6062
eco “process_config.expvar_port: 6063” » /etc/datadog-agent/datadog.yaml
eco “Datadog Agent is installed”
mientras[ -z $DB_DRIVER_PORT ]; haz
si [ -e “/tmp/driver-env.sh” ]; entonces
DB_DRIVER_PORT=”$(grep -i “CONF_UI_PORT” /tmp/driver-env.sh | cut -d’=’ -f2)"
fi
eco “Waiting 2 seconds for DB_DRIVER_PORT”
sleep 2
hecho
eco “DB_DRIVER_PORT=$DB_DRIVER_PORT”
ESCRIBIR ARCHIVO DE CONFIGURACIÓN PARA INTEGRACIÓN DE SPARK CON MÉTRICAS DE STREAMING ESTRUCTURADAS ACTIVADAS
MODIFICAR PARA INCLUIR OTRAS OPCIONES EN spark.d/conf.yaml.example
eco “init_config:
instancias:
- spark_url: http://${DB_DRIVER_IP}:${DB_DRIVER_PORT}
spark_cluster_mode: spark_driver_mode
cluster_name: ${DB_CLUSTER_NAME}
streaming_metrics: true
executor_level_metrics: true
logs:
- tipo: archivo
ruta: /databricks/driver/Logs/.log
fuente: spark
servicio: databricks
log_processing_rules:
- tipo: multi_line
nombre: new_log_start_with_date
patrón: \d{2,4}[-/]\d{2,4}[-/]\d{2,4}.” > /etc/datadog-agent/conf.d/spark.d/spark.yaml
eco “Spark integration configured”
ACTIVAR LOGS EN datadog.yaml PARA RECOPILAR LOGS DEL CONTROLADOR
sed -i ‘/.logs_enabled:./a logs_enabled: true’ /etc/datadog-agent/datadog.yaml
fi
eco “Restart the agent”
sudo service datadog-agent restart
EOF
chmod a+x /tmp/start_datadog.sh
/tmp/start_datadog.sh » /tmp/datadog_start.log 2>&1 & disown
Instale el Datadog Agent en los nodos controlador y trabajador del clúster
Instale el Datadog Agent en los nodos controlador y trabajador del clúster
Deberás definir el valor de la variable `DD_API_KEY` en el script.
#!/bin/bash
cat <<EOF > /tmp/start_datadog.sh
#!/bin/bash
fecha -u +"%Y-%m-%d %H:%M:%S UTC"
eco "Running on the driver? \$DB_IS_DRIVER"
eco "Driver ip: \$DB_DRIVER_IP"
DB_CLUSTER_NAME=$(echo "$DB_CLUSTER_NAME" | sed -e 's/ /_/g' -e "s/'/_/g")
DD_API_KEY='<YOUR_API_KEY>'
si [[ \${DB_IS_DRIVER} = "TRUE" ]]; entonces
eco "Installing Datadog Agent on the driver (master node)."
# CONFIGURAR ETIQUETAS (TAGS) DEL HOST PARA EL CONTROLADOR
DD_TAGS="entorno:\${DD_ENV}","databricks_cluster_id:\${DB_CLUSTER_ID}","databricks_cluster_name:\${DB_CLUSTER_NAME}","spark_host_ip:\${DB_DRIVER_IP}","spark_node:driver","databricks_instance_type:\${DB_INSTANCE_TYPE}","databricks_is_job_cluster:\${DB_IS_JOB_CLUSTER}"
# INSTALAR LA ÚLTIMA VERSIÓN DEL DATADOG AGENT PARA LOS NODOS CONTROLADOR Y TRABAJADOR
DD_INSTALL_ONLY=true \
DD_API_KEY=\$DD_API_KEY \
DD_HOST_TAGS=\$DD_TAGS \
DD_HOSTNAME="\$(hostname | xargs)" \
DD_SITE="\${DD_SITE:-datadoghq.com}" \
bash -c "\$(curl -L https://s3.amazonaws.com/dd-agent/scripts/install_script_agent7.sh)"
eco "Datadog Agent is installed"
mientras [ -z \$DB_DRIVER_PORT ]; haz
si [ -e "/tmp/driver-env.sh" ]; entonces
DB_DRIVER_PORT="\$(grep -i "CONF_UI_PORT" /tmp/driver-env.sh | cut -d'=' -f2)"
fi
eco "Waiting 2 seconds for DB_DRIVER_PORT"
sleep 2
hecho
eco "DB_DRIVER_PORT=\$DB_DRIVER_PORT"
# ESCRIBIR EL ARCHIVO DE CONFIGURACIÓN PARA LA INTEGRACIÓN DE SPARK CON MÉTRICAS DE STREAMING ESTRUCTURADAS ACTIVADAS
# MODIFICAR PARA INCLUIR OTRAS OPCIONES EN spark.d/conf.yaml.example
eco "init_config:
instancias:
- spark_url: http://\${DB_DRIVER_IP}:\${DB_DRIVER_PORT}
spark_cluster_mode: spark_driver_mode
cluster_name: \${DB_CLUSTER_NAME}
streaming_metrics: true
executor_level_metrics: true
logs:
- tipo: archivo
ruta: /databricks/driver/logs/*.log
fuente: spark
servicio: databricks
log_processing_rules:
- tipo: multi_line
nombre: new_log_start_with_date
patrón: \d{2,4}[\-\/]\d{2,4}[\-\/]\d{2,4}.*" > /etc/datadog-agent/conf.d/spark.d/spark.yaml
eco "Spark integration configured"
# ACTIVAR LOGS EN datadog.yaml PARA RECOPILAR LOGS DEL CONTROLADOR
sed -i '/.*logs_enabled:.*/a logs_enabled: true' /etc/datadog-agent/datadog.yaml
o
eco "Installing Datadog Agent on the worker."
# CONFIGURAR ETIQUETAS (TAGS) DEL HOST PARA TRABAJADORES
DD_TAGS="environment:\${DD_ENV}","databricks_cluster_id:\${DB_CLUSTER_ID}","databricks_cluster_name:\${DB_CLUSTER_NAME}","spark_host_ip:\${SPARK_LOCAL_IP}","spark_node:worker","databricks_instance_type:\${DB_INSTANCE_TYPE}","databricks_is_job_cluster:\${DB_IS_JOB_CLUSTER}"
# INSTALAR LA ÚLTIMA VERSIÓN DEL DATADOG AGENT 7 EN LOS NODOS CONTROLADOR Y TRABAJADOR
# CONFIGURAR NOMBRE DEL HOST EXPLÍCITAMENTE EN datadog.yaml PARA IMPEDIR QUE EL AGENT FALLE EN LA VERSIÓN 7.40+
# CONSULTA https://github.com/DataDog/datadog-agent/issues/14152 PARA CAMBIAR
DD_INSTALL_ONLY=true DD_API_KEY=\$DD_API_KEY DD_HOST_TAGS=\$DD_TAGS DD_HOSTNAME="\$(hostname | xargs)" bash -c "\$(curl -L https://s3.amazonaws.com/dd-agent/scripts/install_script_agent7.sh)"
eco "Datadog Agent is installed"
fi
# Evitar conflictos en el puerto 6062
eco "process_config.expvar_port: 6063" >> /etc/datadog-agent/datadog.yaml
eco "Restart the agent"
sudo service datadog-agent restart
EOF
chmod a+x /tmp/start_datadog.sh
/tmp/start_datadog.sh >> /tmp/datadog_start.log 2>&1 & disown
Con un script de inicio de ámbito de clúster
Los scripts de inicio de ámbito de clúster son scripts de inicio definidos en la configuración del clúster. Los scripts de inicio de ámbito de clúster se aplican a los clústeres que creas y a los creados para ejecutar trabajos. Databricks admite la configuración y el almacenamiento de scripts de inicio a través de:
- Archivos de área de trabajo
- Volúmenes de Unity Catalog
- Almacenamiento de objetos en la nube
Utiliza la interfaz de usuario de Databricks para editar el clúster y ejecutar el script de inicio:
- Elige uno de los siguientes scripts para instalar el Agent en el controlador o en los nodos controlador y trabajador del clúster.
- Modifica el script para adaptarlo a tus necesidades. Por ejemplo, puedes añadir etiquetas (tags) o definir una configuración específica para la integración.
- Guarda el script en tu área de trabajo con el menú Área de trabajo de la izquierda. Si utilizas Unity Catalog Volume, guarda el script en tu Volume con el menú Catalog de la izquierda.
- En la página de configuración del clúster, haz clic en el conmutador de opciones Avanzadas.
- En las Variables de entorno, especifica la variable de entorno
DD_API_KEY y, opcionalmente, las variables de entorno DD_ENV y DD_SITE. - Ve a la pestaña Scripts de inicio.
- En el menú desplegable Destino, selecciona el tipo de destino
Workspace. Si utilizas Unity Catalog Volume, en el menú desplegable Destino, selecciona el tipo de destino Volume. - Especifica una ruta al script de inicio.
- Haz clic en el botón Añadir.
Si guardaste tu datadog_init_script.sh directamente en el área de trabajo Shared, puedes acceder al archivo en la siguiente ruta: /Shared/datadog_init_script.sh.
Si guardaste tu datadog_init_script.sh directamente en un área de trabajo del usuario, puedes acceder al archivo en la siguiente ruta: /Users/$EMAIL_ADDRESS/datadog_init_script.sh.
Si guardaste to datadog_init_script.sh directamente en un Unity Catalog Volume, puedes acceder al archivo en la siguiente ruta: /Volumes/$VOLUME_PATH/datadog_init_script.sh.
Puedes encontrar más información sobre los scripts de inicio del clúster en la documentación oficial de Databricks.
Instala el Datadog Agent en el controlador
Instala el Datadog Agent en el nodo controlador del clúster.
``script de shell
#!/bin/bash
cat «EOF > /tmp/start_datadog.sh
#!/bin/bash
fecha -u +"%Y-%m-%d %H:%M:%S UTC"
eco “Running on the driver? $DB_IS_DRIVER”
eco “Driver ip: $DB_DRIVER_IP”
DB_CLUSTER_NAME=$(echo “$DB_CLUSTER_NAME” | sed -e ’s/ //g’ -e “s/’//g”)
si [[ ${DB_IS_DRIVER} = “TRUE” ]]; entonces
eco “Installing Datadog Agent on the driver…”
DD_TAGS=“entorno:${DD_ENV}”,“databricks_cluster_id:${DB_CLUSTER_ID}”,“databricks_cluster_name:${DB_CLUSTER_NAME}”,“spark_host_ip:${DB_DRIVER_IP}”,“spark_node:driver”,“databricks_instance_type:${DB_INSTANCE_TYPE}”,“databricks_is_job_cluster:${DB_IS_JOB_CLUSTER}”
INSTALAR LA ÚLTIMA VERSIÓN DEL DATADOG AGENT 7 EN LOS NODOS CONTROLADOR Y TRABAJADOR
DD_INSTALL_ONLY=true
DD_API_KEY=$DD_API_KEY
DD_HOST_TAGS=$DD_TAGS
DD_HOSTNAME="$(hostname | xargs)"
DD_SITE="${DD_SITE:-datadoghq.com}"
bash -c “$(curl -L https://s3.amazonaws.com/dd-agent/scripts/install_script_agent7.sh)"
Evitar conflictos en el puerto 6062
eco “process_config.expvar_port: 6063” » /etc/datadog-agent/datadog.yaml
eco “Datadog Agent is installed”
si bien [ -z $DB_DRIVER_PORT ]; haz
si [ -e “/tmp/driver-env.sh” ]; entonces
DB_DRIVER_PORT=”$(grep -i “CONF_UI_PORT” /tmp/driver-env.sh | cut -d’=’ -f2)"
fi
eco “Waiting 2 seconds for DB_DRIVER_PORT”
sleep 2
hecho
eco “DB_DRIVER_PORT=$DB_DRIVER_PORT”
ESCRIBIR ARCHIVO DE CONFIGURACIÓN DE INTEGRACIÓN DE SPARK CON MÉTRICAS DE STREAMING ESTRUCTURADAS ACTIVADAS
MODIFICAR PARA INCLUIR OTRAS OPCIONES EN spark.d/conf.yaml.example
eco “init_config:
instancias:
- spark_url: http://${DB_DRIVER_IP}:${DB_DRIVER_PORT}
spark_cluster_mode: spark_driver_mode
cluster_name: ${DB_CLUSTER_NAME}
streaming_metrics: true
executor_level_metrics: true
logs:
- tipo: archivo
ruta: /databricks/driver/Logs/.log
fuente: spark
servicio: databricks
log_processing_rules:
- tipo: multi_line
nombre: new_log_start_with_date
patrón: \d{2,4}[-/]\d{2,4}[-/]\d{2,4}.” > /etc/datadog-agent/conf.d/spark.d/spark.yaml
eco “Spark integration configured”
ACTIVAR LOGS EN Datadog.yaml PARA RECOPILAR LOGS DEL CONTROLADOR
sed -i ‘/.logs_enabled:./a logs_enabled: true’ /etc/datadog-agent/datadog.yaml
fi
eco “Restart the agent”
sudo service datadog-agent restart
EOF
chmod a+x /tmp/start_datadog.sh
/tmp/start_datadog.sh » /tmp/datadog_start.log 2>&1 & disown
Instalar el Datadog Agent en los nodos controlador y trabajador
Instalar el Datadog Agent en los nodos controlador y trabajador del clúster
#!/bin/bash
cat <<EOF > /tmp/start_datadog.sh
#!/bin/bash
fecha -u +"%Y-%m-%d %H:%M:%S UTC"
eco "Running on the driver? \$DB_IS_DRIVER"
eco "Driver ip: \$DB_DRIVER_IP"
DB_CLUSTER_NAME=$(echo "$DB_CLUSTER_NAME" | sed -e 's/ /_/g' -e "s/'/_/g")
si [[ \${DB_IS_DRIVER} = "TRUE" ]]; entonces
eco "Installing Datadog Agent on the driver (master node)."
# CONFIGURAR ETIQUETAS (TAGS) DEL HOST PARA EL CONTROLADOR
DD_TAGS="environment:\${DD_ENV}","databricks_cluster_id:\${DB_CLUSTER_ID}","databricks_cluster_name:\${DB_CLUSTER_NAME}","spark_host_ip:\${DB_DRIVER_IP}","spark_node:driver","databricks_instance_type:\${DB_INSTANCE_TYPE}","databricks_is_job_cluster:\${DB_IS_JOB_CLUSTER}"
# INSTALAR LA ÚLTIMA VERSIÓN DEL DATADOG AGENT 7 EN LOS NODOS CONTROLADOR Y TRABAJADOR
DD_INSTALL_ONLY=true \
DD_API_KEY=\$DD_API_KEY \
DD_HOST_TAGS=\$DD_TAGS \
DD_HOSTNAME="\$(hostname | xargs)" \
DD_SITE="\${DD_SITE:-datadoghq.com}" \
bash -c "\$(curl -L https://s3.amazonaws.com/dd-agent/scripts/install_script_agent7.sh)"
eco "Datadog Agent is installed"
si bien [ -z \$DB_DRIVER_PORT ]; haz
si [ -e "/tmp/driver-env.sh" ]; entonces
DB_DRIVER_PORT="\$(grep -i "CONF_UI_PORT" /tmp/driver-env.sh | cut -d'=' -f2)"
fi
eco "Waiting 2 seconds for DB_DRIVER_PORT"
sleep 2
hecho
eco "DB_DRIVER_PORT=\$DB_DRIVER_PORT"
# ESCRIBIR ARCHIVO DE CONFIGURACIÓN DE INTEGRACIÓN DE SPARK CON MÉTRICAS DE STREAMING ESTRUCTURADAS ACTIVADAS
# MODIFICAR PARA INCLUIR OTRAS OPCIONES EN spark.d/conf.yaml.example
eco "init_config:
instancias:
- spark_url: http://\${DB_DRIVER_IP}:\${DB_DRIVER_PORT}
spark_cluster_mode: spark_driver_mode
cluster_name: \${DB_CLUSTER_NAME}
streaming_metrics: true
executor_level_metrics: true
logs:
- tipo: archivo
ruta: /databricks/driver/logs/*.log
fuente: spark
servicio: databricks
log_processing_rules:
- type: multi_line
nombre: new_log_start_with_date
patrón: \d{2,4}[\-\/]\d{2,4}[\-\/]\d{2,4}.*" > /etc/datadog-agent/conf.d/spark.d/spark.yaml
eco "Spark integration configured"
# ACTIVAR LOGS EN datadog.yaml PARA RECOPILAR LOGS DEL CONTROLADOR
sed -i '/.*logs_enabled:.*/a logs_enabled: true' /etc/datadog-agent/datadog.yaml
o
eco "Installing Datadog Agent on the worker."
# CONFIGURAR ETIQUETAS (TAGS) DEL HOST PARA TRABAJADORES
DD_TAGS="environment:\${DD_ENV}","databricks_cluster_id:\${DB_CLUSTER_ID}","databricks_cluster_name:\${DB_CLUSTER_NAME}","spark_host_ip:\${SPARK_LOCAL_IP}","spark_node:worker","databricks_instance_type:\${DB_INSTANCE_TYPE}","databricks_is_job_cluster:\${DB_IS_JOB_CLUSTER}"
# INSTALAR LA ÚLTIMA VERSIÓN DEL DATADOG AGENT 7 EN LOS NODOS CONTROLADOR Y TRABAJADOR
# CONFIGURAR EL NOMBRE DEL HOST EXPLÍCITAMENTE EN datadog.yaml PARA IMPEDIR QUE EL AGENT FALLE EN LA VERSIÓN 7.40+
# CONSULTA https://github.com/DataDog/datadog-agent/issues/14152 PARA CAMBIOS
DD_INSTALL_ONLY=true DD_API_KEY=\$DD_API_KEY DD_HOST_TAGS=\$DD_TAGS DD_HOSTNAME="\$(hostname | xargs)" bash -c "\$(curl -L https://s3.amazonaws.com/dd-agent/scripts/install_script_agent7.sh)"
eco "Datadog Agent is installed"
fi
# Evitar conflictos en el puerto 6062
eco "process_config.expvar_port: 6063" >> /etc/datadog-agent/datadog.yaml
eco "Restart the agent"
sudo service datadog-agent restart
EOF
chmod a+x /tmp/start_datadog.sh
/tmp/start_datadog.sh >> /tmp/datadog_start.log 2>&1 & disown
Datos recopilados
Métricas
Consulta la documentación de la integración de Spark para obtener una lista de métricas recopiladas.
Checks de servicio
Consulta la documentación de la integración de Spark para obtener la lista de chechs de servicio recopilados.
Eventos
La integración de Databricks no incluye ningún evento.
Solucionar problemas
Puedes solucionar los problemas tú mismo habilitando el terminal web de Databricks o utilizando una notebook Databricks. Consulta la documentación de Solucionar problemas del Agent para obtener información sobre pasos útiles para solucionar problemas.
¿Necesitas ayuda? Ponte en contacto con soporte técnico de Datadog.
Referencias adicionales
Más enlaces, artículos y documentación útiles: