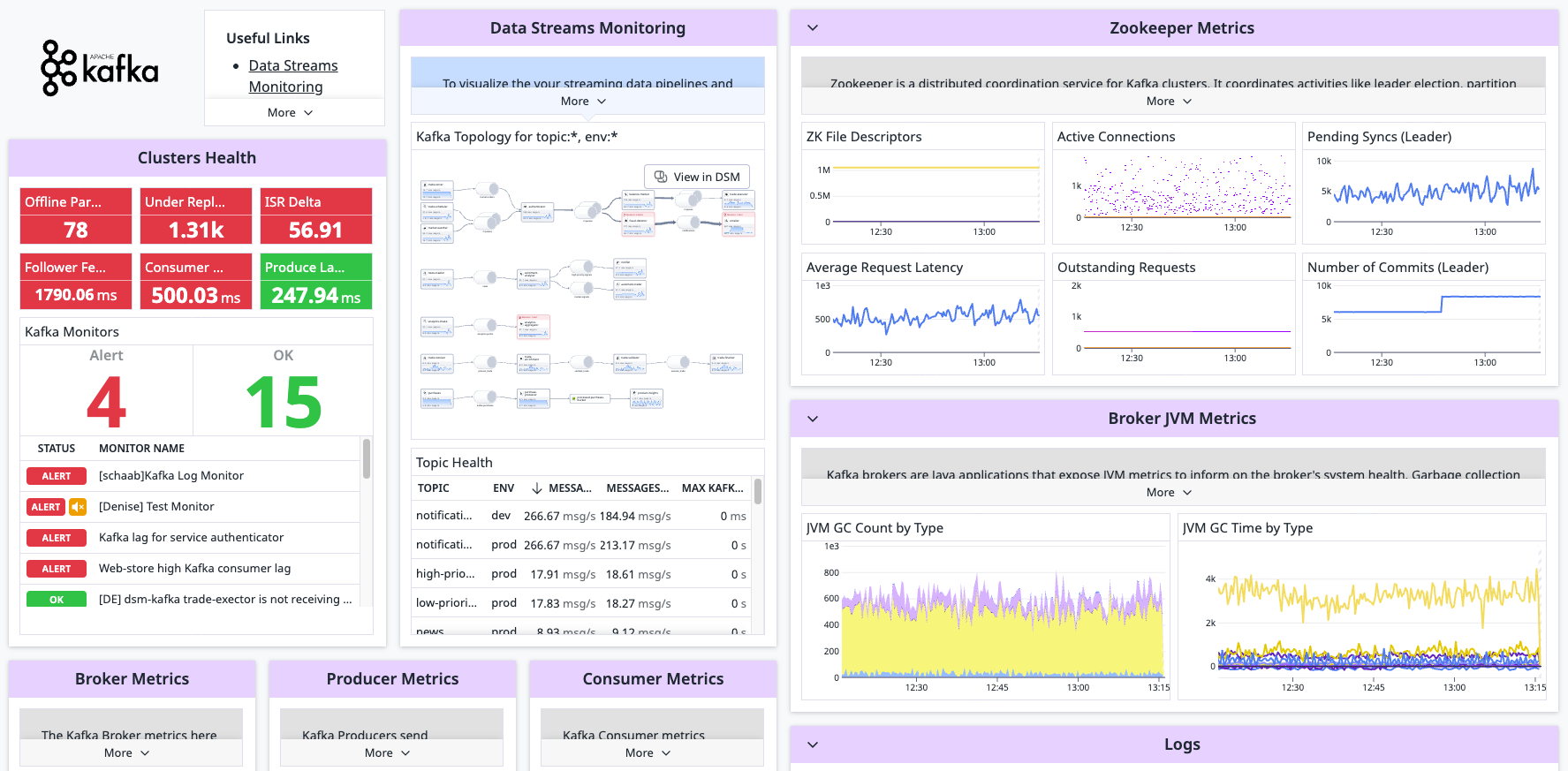
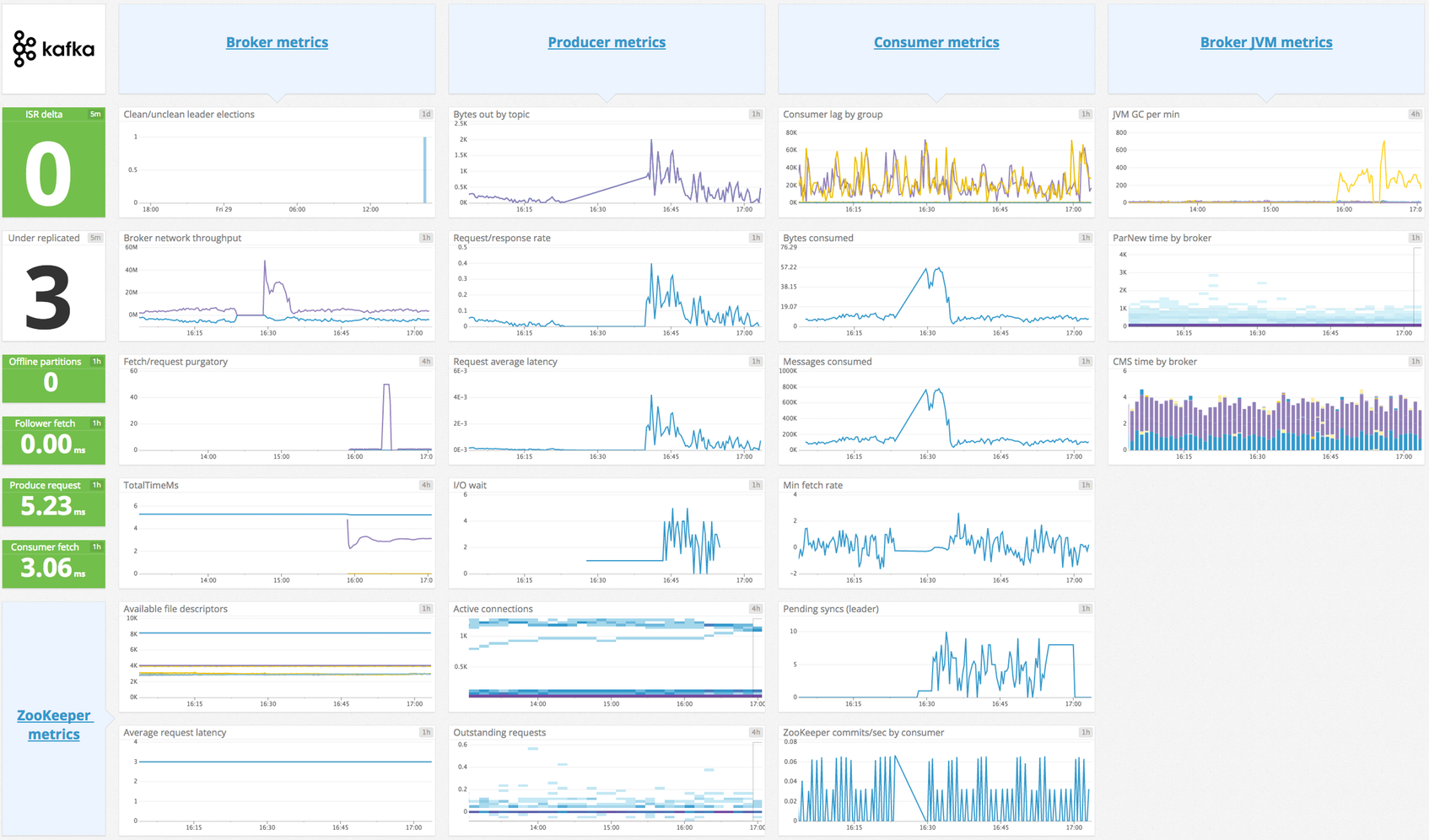
kafka.consumer.bytes_consumed
(gauge) | The average number of bytes consumed per second for a specific topic.
Shown as byte |
kafka.consumer.bytes_in
(gauge) | Consumer bytes in rate.
Shown as byte |
kafka.consumer.delayed_requests
(gauge) | Number of delayed consumer requests.
Shown as request |
kafka.consumer.expires_per_second
(gauge) | Rate of delayed consumer request expiration.
Shown as eviction |
kafka.consumer.fetch_rate
(gauge) | The minimum rate at which the consumer sends fetch requests to a broker.
Shown as request |
kafka.consumer.fetch_size_avg
(gauge) | The average number of bytes fetched per request for a specific topic.
Shown as byte |
kafka.consumer.fetch_size_max
(gauge) | The maximum number of bytes fetched per request for a specific topic.
Shown as byte |
kafka.consumer.kafka_commits
(gauge) | Rate of offset commits to Kafka.
Shown as write |
kafka.consumer.max_lag
(gauge) | Maximum consumer lag.
Shown as offset |
kafka.consumer.messages_in
(gauge) | Rate of consumer message consumption.
Shown as message |
kafka.consumer.records_consumed
(gauge) | The average number of records consumed per second for a specific topic.
Shown as record |
kafka.consumer.records_per_request_avg
(gauge) | The average number of records in each request for a specific topic.
Shown as record |
kafka.consumer.zookeeper_commits
(gauge) | Rate of offset commits to ZooKeeper.
Shown as write |
kafka.expires_sec
(gauge) | Rate of delayed producer request expiration.
Shown as eviction |
kafka.follower.expires_per_second
(gauge) | Rate of request expiration on followers.
Shown as eviction |
kafka.log.flush_rate.rate
(gauge) | Log flush rate.
Shown as flush |
kafka.messages_in.rate
(gauge) | Incoming message rate.
Shown as message |
kafka.net.bytes_in.rate
(gauge) | Incoming byte rate.
Shown as byte |
kafka.net.bytes_out
(gauge) | Outgoing byte total.
Shown as byte |
kafka.net.bytes_out.rate
(gauge) | Outgoing byte rate.
Shown as byte |
kafka.net.bytes_rejected.rate
(gauge) | Rejected byte rate.
Shown as byte |
kafka.net.processor.avg.idle.pct.rate
(gauge) | Average fraction of time the network processor threads are idle.
Shown as fraction |
kafka.producer.available_buffer_bytes
(gauge) | The total amount of buffer memory that is not being used (either unallocated or in the free list)
Shown as byte |
kafka.producer.batch_size_avg
(gauge) | The average number of bytes sent per partition per-request.
Shown as byte |
kafka.producer.batch_size_max
(gauge) | The max number of bytes sent per partition per-request.
Shown as byte |
kafka.producer.buffer_bytes_total
(gauge) | The maximum amount of buffer memory the client can use (whether or not it is currently used).
Shown as byte |
kafka.producer.bufferpool_wait_ratio
(gauge) | The fraction of time an appender waits for space allocation. |
kafka.producer.bufferpool_wait_time
(gauge) | The fraction of time an appender waits for space allocation. |
kafka.producer.bufferpool_wait_time_ns_total
(gauge) | The total time in nanoseconds an appender waits for space allocation.
Shown as nanosecond |
kafka.producer.bytes_out
(gauge) | Producer bytes out rate.
Shown as byte |
kafka.producer.compression_rate
(gauge) | The average compression rate of record batches for a topic
Shown as fraction |
kafka.producer.compression_rate_avg
(rate) | The average compression rate of record batches.
Shown as fraction |
kafka.producer.delayed_requests
(gauge) | Number of producer requests delayed.
Shown as request |
kafka.producer.expires_per_seconds
(gauge) | Rate of producer request expiration.
Shown as eviction |
kafka.producer.io_wait
(gauge) | Producer I/O wait time.
Shown as nanosecond |
kafka.producer.message_rate
(gauge) | Producer message rate.
Shown as message |
kafka.producer.metadata_age
(gauge) | The age in seconds of the current producer metadata being used.
Shown as second |
kafka.producer.record_error_rate
(gauge) | The average per-second number of errored record sends for a topic
Shown as error |
kafka.producer.record_queue_time_avg
(gauge) | The average time in ms record batches spent in the record accumulator.
Shown as millisecond |
kafka.producer.record_queue_time_max
(gauge) | The maximum time in ms record batches spent in the record accumulator.
Shown as millisecond |
kafka.producer.record_retry_rate
(gauge) | The average per-second number of retried record sends for a topic
Shown as record |
kafka.producer.record_send_rate
(gauge) | The average number of records sent per second for a topic
Shown as record |
kafka.producer.record_size_avg
(gauge) | The average record size.
Shown as byte |
kafka.producer.record_size_max
(gauge) | The maximum record size.
Shown as byte |
kafka.producer.records_per_request
(gauge) | The average number of records sent per second.
Shown as record |
kafka.producer.request_latency_avg
(gauge) | Producer average request latency.
Shown as millisecond |
kafka.producer.request_latency_max
(gauge) | The maximum request latency in ms.
Shown as millisecond |
kafka.producer.request_rate
(gauge) | Number of producer requests per second.
Shown as request |
kafka.producer.requests_in_flight
(gauge) | The current number of in-flight requests awaiting a response.
Shown as request |
kafka.producer.response_rate
(gauge) | Number of producer responses per second.
Shown as response |
kafka.producer.throttle_time_avg
(gauge) | The average time in ms a request was throttled by a broker.
Shown as millisecond |
kafka.producer.throttle_time_max
(gauge) | The maximum time in ms a request was throttled by a broker.
Shown as millisecond |
kafka.producer.waiting_threads
(gauge) | The number of user threads blocked waiting for buffer memory to enqueue their records.
Shown as thread |
kafka.replication.active_controller_count
(gauge) | Number of active controllers in the cluster.
Shown as node |
kafka.replication.isr_expands.rate
(gauge) | Rate of replicas joining the ISR pool.
Shown as node |
kafka.replication.isr_shrinks.rate
(gauge) | Rate of replicas leaving the ISR pool.
Shown as node |
kafka.replication.leader_count
(gauge) | Number of leaders on this broker.
Shown as node |
kafka.replication.leader_elections.rate
(gauge) | Leader election rate.
Shown as event |
kafka.replication.max_lag
(gauge) | Maximum lag in messages between the follower and leader replicas.
Shown as offset |
kafka.replication.offline_partitions_count
(gauge) | Number of partitions that don't have an active leader. |
kafka.replication.partition_count
(gauge) | Number of partitions across all topics in the cluster. |
kafka.replication.unclean_leader_elections.rate
(gauge) | Unclean leader election rate.
Shown as event |
kafka.replication.under_min_isr_partition_count
(gauge) | Number of under min ISR partitions. |
kafka.replication.under_replicated_partitions
(gauge) | Number of under replicated partitions. |
kafka.request.channel.queue.size
(gauge) | Number of queued requests.
Shown as request |
kafka.request.fetch.failed.rate
(gauge) | Client fetch request failures rate.
Shown as request |
kafka.request.fetch_consumer.rate
(gauge) | Fetch consumer requests rate.
Shown as request |
kafka.request.fetch_consumer.time.99percentile
(gauge) | Total time in ms to serve the specified request.
Shown as millisecond |
kafka.request.fetch_consumer.time.avg
(gauge) | Total time in ms to serve the specified request.
Shown as millisecond |
kafka.request.fetch_follower.rate
(gauge) | Fetch follower requests rate.
Shown as request |
kafka.request.fetch_follower.time.99percentile
(gauge) | Total time in ms to serve the specified request.
Shown as millisecond |
kafka.request.fetch_follower.time.avg
(gauge) | Total time in ms to serve the specified request.
Shown as millisecond |
kafka.request.fetch_request_purgatory.size
(gauge) | Number of requests waiting in the producer purgatory.
Shown as request |
kafka.request.handler.avg.idle.pct.rate
(gauge) | Average fraction of time the request handler threads are idle.
Shown as fraction |
kafka.request.metadata.time.99percentile
(gauge) | Time for metadata requests for 99th percentile.
Shown as millisecond |
kafka.request.metadata.time.avg
(gauge) | Average time for metadata request.
Shown as millisecond |
kafka.request.offsets.time.99percentile
(gauge) | Time for offset requests for 99th percentile.
Shown as millisecond |
kafka.request.offsets.time.avg
(gauge) | Average time for an offset request.
Shown as millisecond |
kafka.request.produce.failed.rate
(gauge) | Failed produce requests rate.
Shown as request |
kafka.request.produce.rate
(gauge) | Produce requests rate.
Shown as request |
kafka.request.produce.time.99percentile
(gauge) | Time for produce requests for 99th percentile.
Shown as millisecond |
kafka.request.produce.time.avg
(gauge) | Average time for a produce request.
Shown as millisecond |
kafka.request.producer_request_purgatory.size
(gauge) | Number of requests waiting in the producer purgatory
Shown as request |
kafka.request.update_metadata.time.99percentile
(gauge) | Time for update metadata requests for 99th percentile.
Shown as millisecond |
kafka.request.update_metadata.time.avg
(gauge) | Average time for a request to update metadata.
Shown as millisecond |
kafka.server.socket.connection_count
(gauge) | Number of currently open connections to the broker.
Shown as connection |
kafka.session.fetch.count
(gauge) | Number of fetch sessions. |
kafka.session.fetch.eviction
(gauge) | Eviction rate of fetch session.
Shown as event |
kafka.session.zookeeper.disconnect.rate
(gauge) | Zookeeper client disconnect rate.
Shown as event |
kafka.session.zookeeper.expire.rate
(gauge) | Zookeeper client session expiration rate.
Shown as event |
kafka.session.zookeeper.readonly.rate
(gauge) | Zookeeper client readonly rate.
Shown as event |
kafka.session.zookeeper.sync.rate
(gauge) | Zookeeper client sync rate.
Shown as event |
kafka.topic.messages_in.rate
(gauge) | Incoming message rate by topic
Shown as message |
kafka.topic.net.bytes_in.rate
(gauge) | Incoming byte rate by topic.
Shown as byte |
kafka.topic.net.bytes_out.rate
(gauge) | Outgoing byte rate by topic.
Shown as byte |
kafka.topic.net.bytes_rejected.rate
(gauge) | Rejected byte rate by topic.
Shown as byte |